8月多模态论文阅读
前置知识
Attention
手撕Transformer代码:
Self-Attention
Basic Equation:$Attention(Q,K,V) = SoftMax(\frac{QK^T}{\sqrt{d_k}})V$
Self-Attention多用于Transformer-encoder架构中,可以将文本,图片,音频等不同模态均转换为特征空间的向量表示。
假设经过前期的encoding,初始向量$f$大小为$N\times L$,query, key, value矩阵分别为$M_Q, M_K, M_V$,大小为$L \times L$
- $Q = f \times M_Q (N\times L)$, $K = f \times M_K (N\times L)$,$V = f \times M_V (N\times L)$
- $QK^T$是大小为$N \times N$的矩阵,表征不同object之间的similarity(例如在文本模态中,N所在的维度通常表示word)
- $d_K$为经过key矩阵之后,特征向量的维度,qkv矩阵的大小并不一定总为$L \times L$,输出维度可根据需要进行改变
- SoftMax将归一化每一行query similarity的概率,即最后输出的$N \times N$矩阵代表有多少概率相关
- 最终输出大小仍旧为$N \times L$,代表利用QK所算出来的percentage重新分配Value的注意力分数
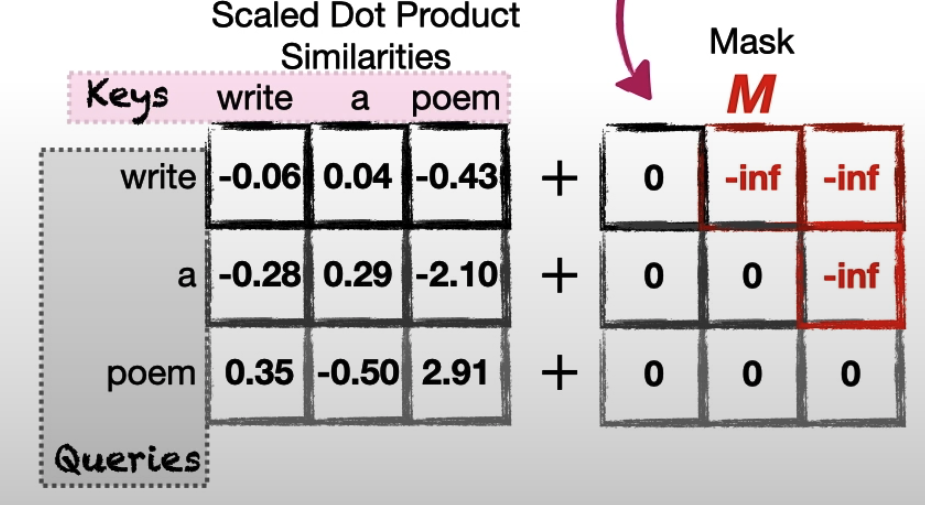
Masked Self-Attention
Basic Equation:$Attention(Q,K,V,M) = SoftMax(\frac{QK^T}{\sqrt{d_k}} + M)V$
在Transfomer-decoder中,通常为了完成生成任务,在训练时候不需要模型看到后续的输出,利用mask使其只关注当前以及之前的token,进而计算注意力分数
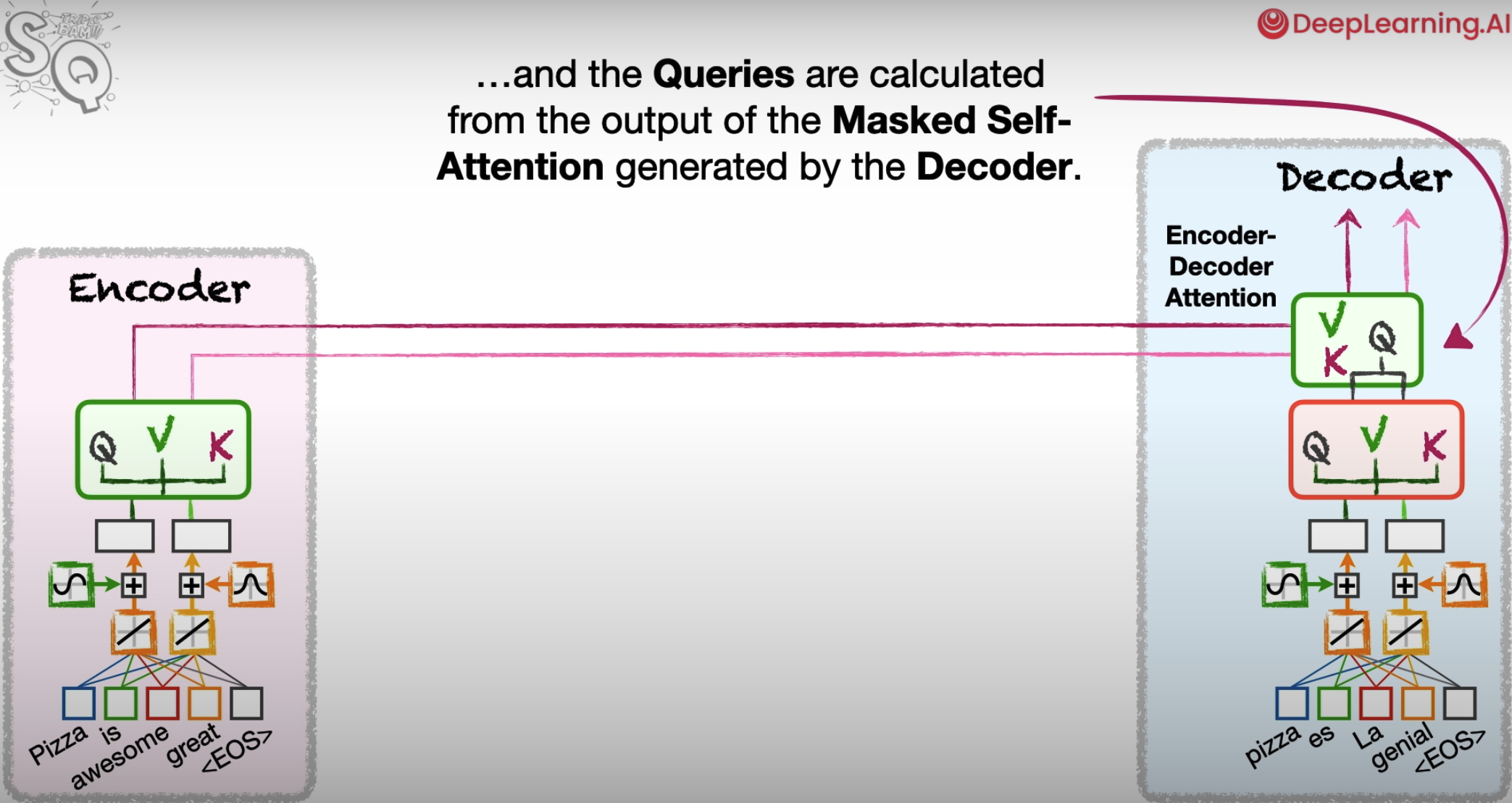
Cross-Attention
通常存在于Encoder-Docoder Attention中,通过利用Encoder中的V,K,与Decoder中的Q进行注意力机制的运算。在多模态中,Encoder可以是图像模态,Decoder输入为文本模态,可以做到将图片的信息融合进文本中。
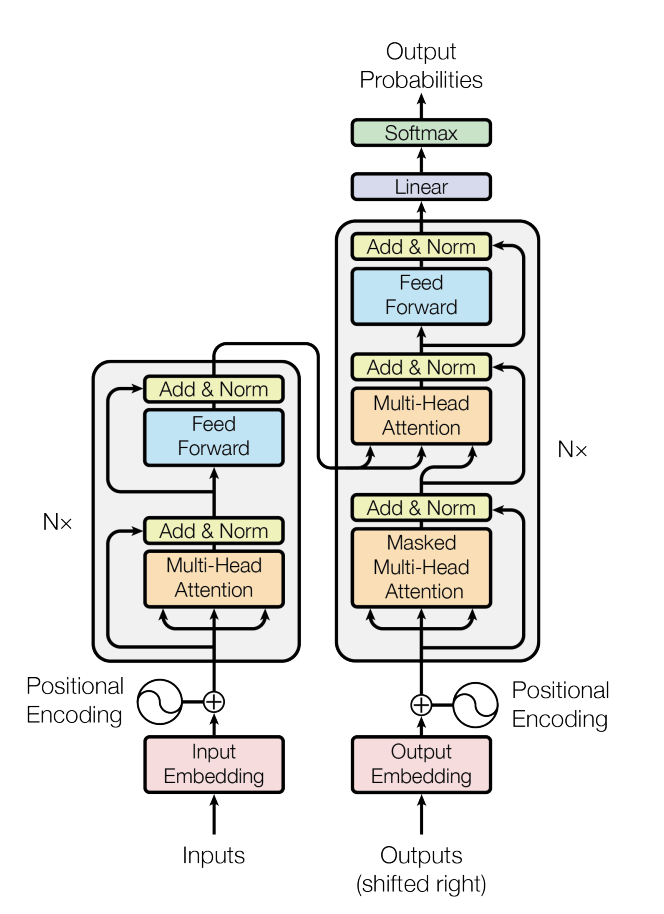
Transformer
VIT
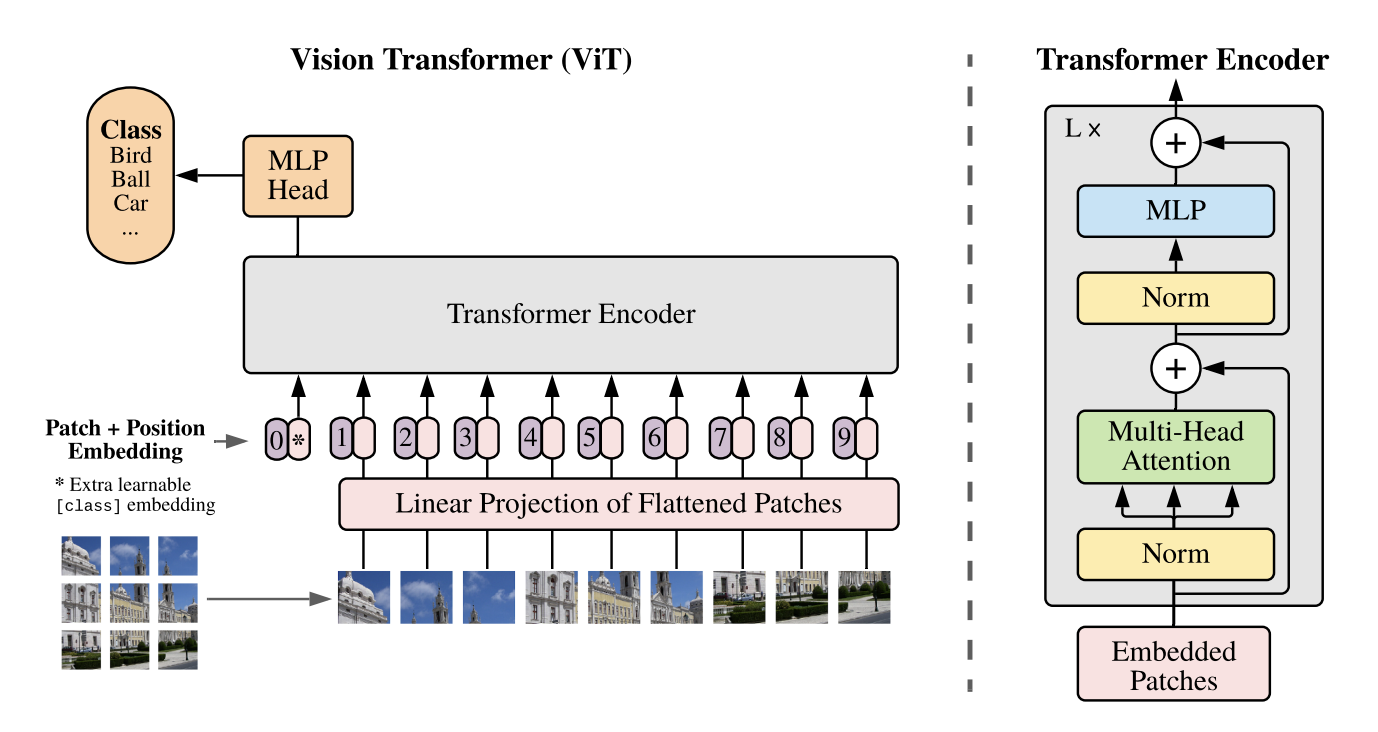
将图片分割成16*16的patch,对每一个patch输入到一个线性投影层中得到特征向量,直接将其输入到Transformer-encoder中,实现较好的视觉领域大规模预训练结果。
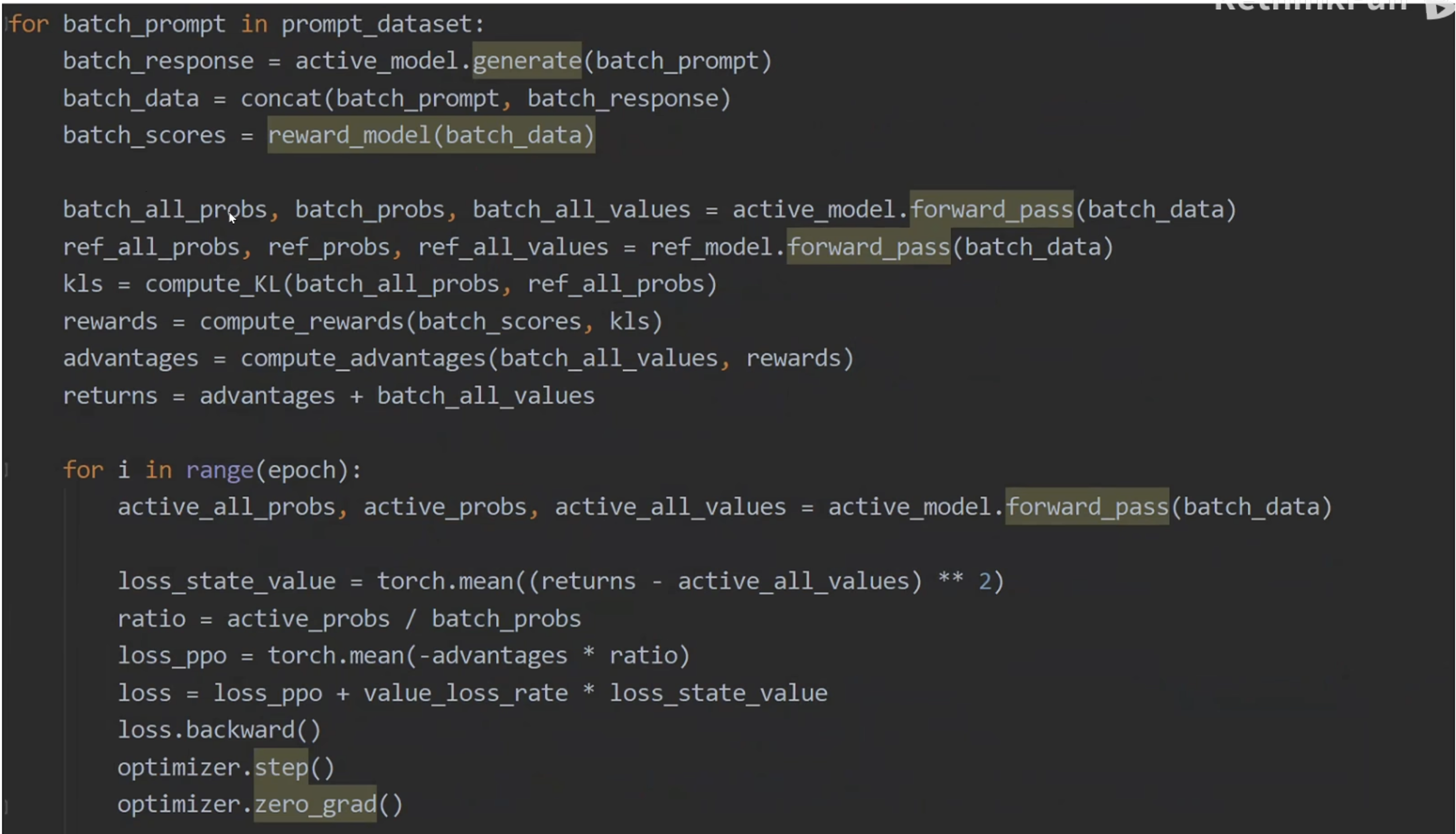
PPO算法
前置知识
具体PPO算法可以参考上述文档,此处只给出必要的公式:
PPO Loss = $-\frac{1}{N}\sum_{n = 1}^{N}\sum_{t = 1}^{T_n}A_{\theta^{‘}}^{GAE}(s_t^n, a_t^n)\frac{p_{\theta}(a_t^n | s_t^n)}{p_{\theta^{‘}}(a_t^n | s_t^n)} + \beta KL(p_{\theta}, p_{\theta^{‘}})$
其中,$A_{\theta}^{GAE}(s_t, a) = \sum_{i = 0}^{\infty}(\gamma \lambda)^i \delta_{t+i}^{V}$,$\delta_t^V = r_t + \gamma V_{\theta}(s_{t+1}) - V_{\theta}(s_t)$
在LLM训练中,状态$s$为至今为止所输入的所有token,而动作$a$为LLM输出的next token
PPO in LLM
四个模型:
- Reference LLM:进行重要性采样的大模型,一般将经过预训练+SFT微调之后,但还未进行RL post training的LLM当作Reference LLM
- Active LLM:为主要训练模型
- Reward LLM:输出层为1,为LLM的回复进行打分
- State-Value LLM:输出层为1,对LLM回复的任意state输出其value
- 注:为了保证memory efficient,除去Reference LLM为整个LLM以外,其余模型只需要加载其lora参数即可。其中,Active LLM和State-Value共用一套lora。
reward模型训练:
- 输出一个分数,表征对LLM回复质量的评分
- 训练方式:对于一个问题,给出一好一坏两个回答,训练loss为$-logsigmoid(chosen - rejected)$
Reward for each token:由于reward模型只对完整输出进行打分,而在PPO算法中,每一个state均需要有一个reward,工程上通过计算reference model和active model在输出层中概率分布的KL散度,定义$-0.2 \times KL + reward$为每一个state的奖励。其中$reward = (0, 0, …, r)$,只有最终输出才有reward模型计算的分数
State-Value label:$V_{label}(s_t) = A_t^{GAE} + V(s_t)$
重要性采样:
MLLM-Pretrain
CLIP
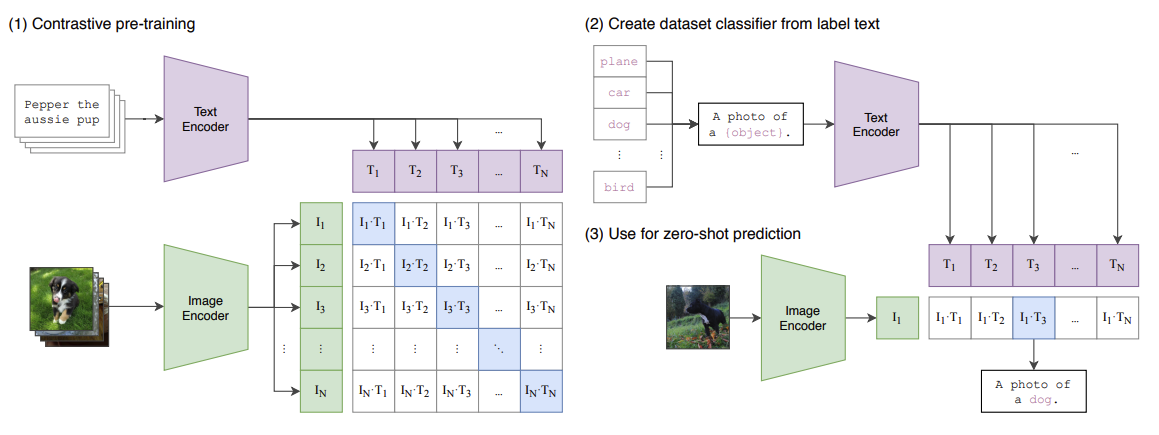
通过海量的弱监督文本对通过对比学习,将图片和文本通过各自的预训练模型获得的编码向量在向量空间上对齐。
特点:多模态融合部分采用最简单的点积方式,运算速度快,适用于图文检索,但对于视觉推理,视觉问答等下游任务表现不足。
ViLT
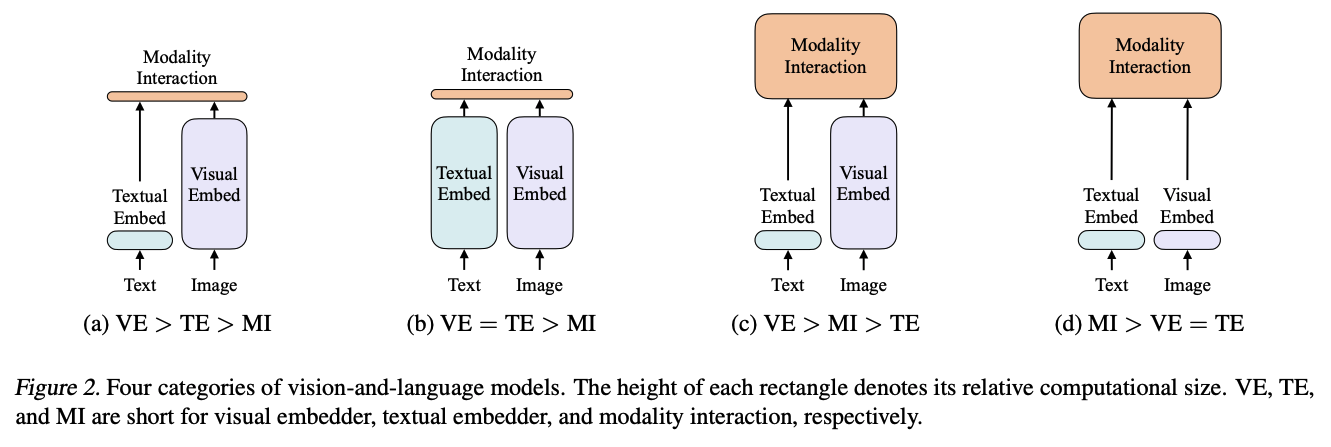
先前论文在提取视觉特征时,均将Visual Embed层做的非常大,ViLT认为这增大了运算负担以及时间开销,所以他们提出(d)中结构,在文本与视觉特征提取时,均用轻量级extractor,但在模态融合时,运用足够大的transformer encoder
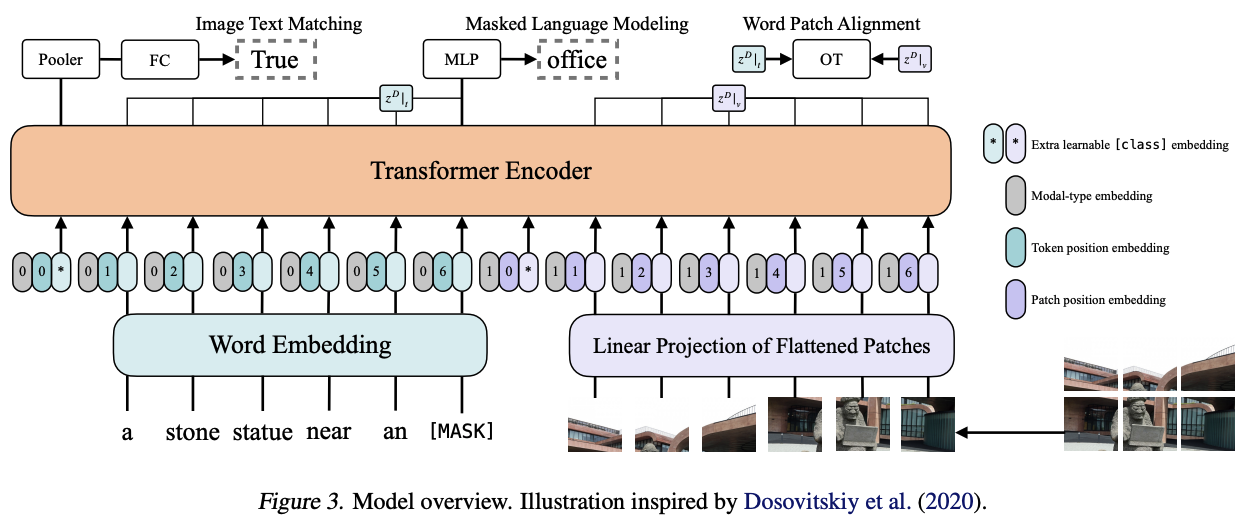
- 文本与图片的特征预提取:
- 文本:word embedding + position embedding
- 图片:分割成patch之后,简单的linear projection + position embedding
- 文本与图片均各有一个[CLS]特征向量,其中文本的[CLS]具有全局特征信息
- Transformer Encoder的初始权重来自于pre-trained ViT而非BERT(在多模态融合中,预先存储视觉信息往往会比预先存储文本信息,训练效果更好)
- 训练约束
- ITM (Image Text Matching):二分类任务,从文本的[CLS]向量中外接一个FC分类头,用来判断当前图片-文本对是否匹配
- MLM (Masked Language Modeling):训练方法来自于BERT:在训练中,随机选15%的token,替换为[MASK],在经过transformer融合后,将该位置的向量外接一个MLP,用来预测被[MASK]的词是什么。为了保证下游任务不会因为没有[MASK]而造成pre-train阶段的过拟合,在15%被选中的token中:
- 有80%概率沿用[MASK]
- 10%概率替换为随机token
- 10%概率不做任何替换,保留原token
- 小技巧:
- Whole Word Masking:避免mask token为单词一小部分,模型学习时候可以通过前后词根进行分析,从而没有利用图片信息。因此,每一次需要mask掉整个单词。
- Image Augmentation:RandAugment
ALBEF
- Motivation:
- 现如今多模态大模型,均是经过text and vision encoder之后,直接进行模态融合,但是由于两个encoder本身并没有对齐,这样直接融合效率低
- 现如今unlabel data噪声太大,图片文本pair仅具有weakly-correlated
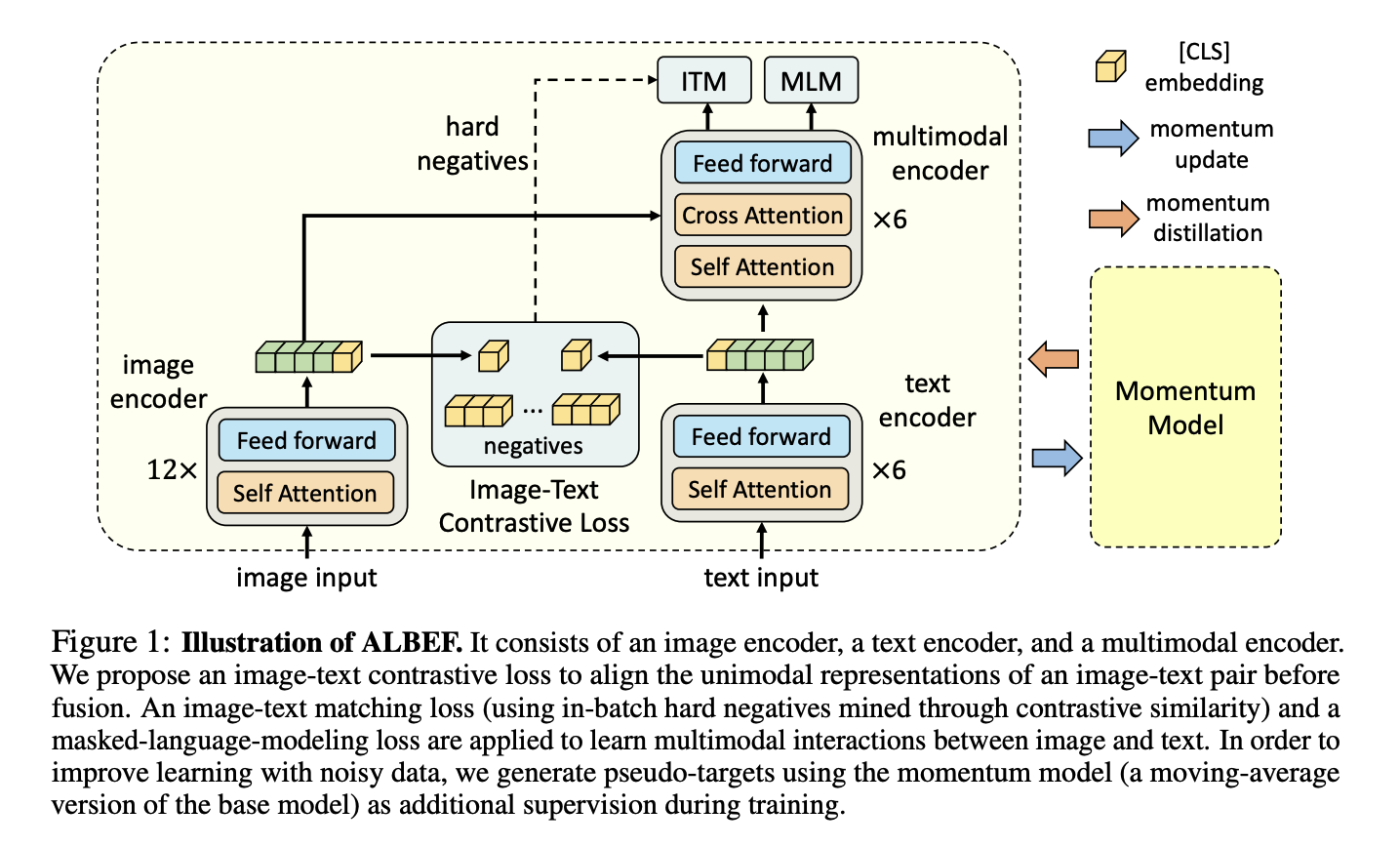
- Solution:
- ITC loss:在进入多模态融合之前,利用对比学习ITC先将多模态特征对齐。
- 引入了Momentum Model,具体详见MoCo
MoCo对比学习伪代码:

有一份初始一模一样的模型,其担任teacher角色,为ITC,MLM提供伪标签,削弱unabel data中图片文本对weakly-correlated的问题
动量模型更新:$y_t = my_{t-1} + (1 - m) x_t$
- Hard Negative Mining:在利用ITM的时候,为了给到更难的负样本从而提高模型的辨别能力,对于每一张图片,从mini-batch中采样1个在ITC中相似度最高的负样本进行学习(或者相似度越高,就越有更高的概率被采样)。每一条文本同理。
VLMo (这个组的工作非常Solid)
- Motivation:
- CLIP-based的方法,利用点乘计算相似度,在检索任务中速度快,效率高。Fusion-based的方法,在视觉推理任务中表现好,但在检索任务中,由于每一次需要通过所有block,计算消耗量大。
- 用更大的数据集训练导致更好的效果在多模态领域没有体现,原因在于没有大体量优质的数据集
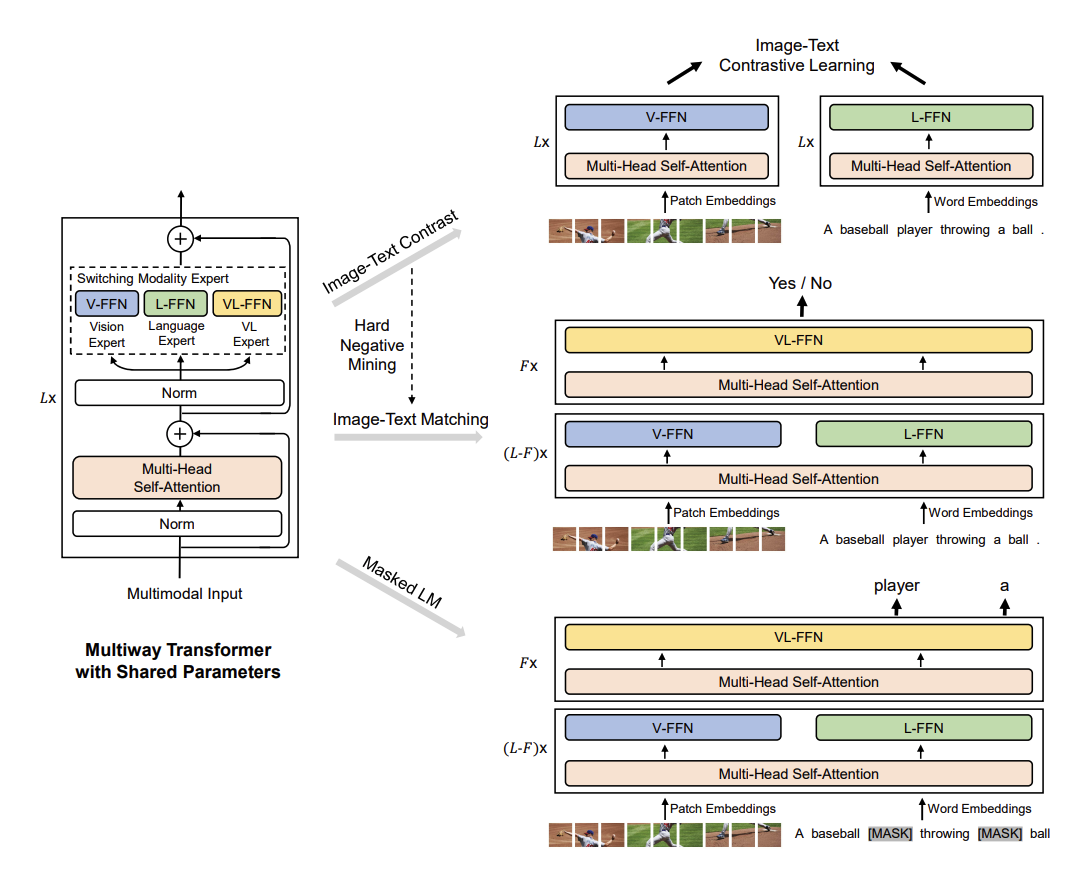
- Solution:
- MoE架构:每一个transformer block的FFN被分为三个前向函数,三个函数共享一个多头注意力层,依据不同模态走不同的FFN
- 首先用大规模的视觉,文本数据集对V-FFN和L-FFN进行pretrain,最后再用多模态数据集对所有参数进行pretrain
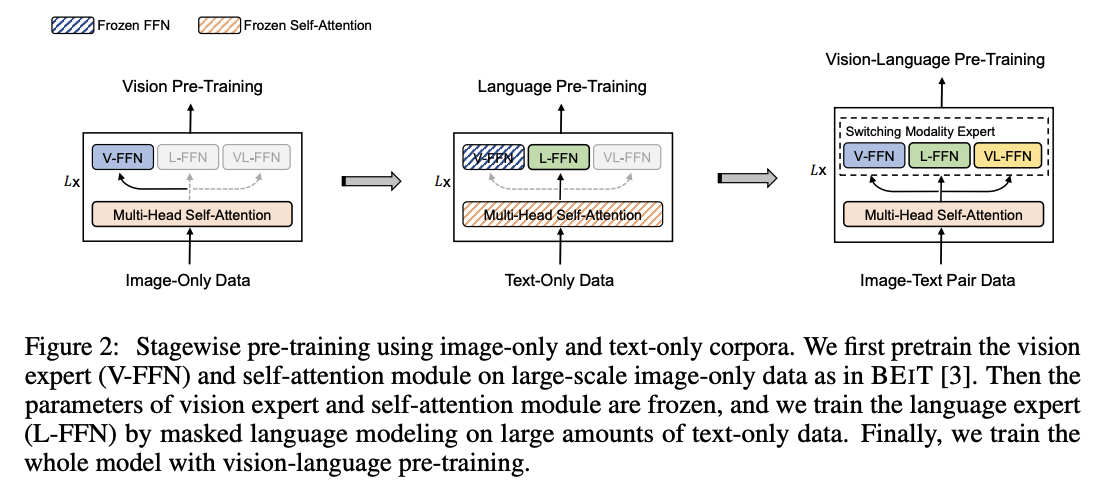
先预训练视觉部分,再冻住相关参数,只训练文本部分。在具有视觉信息的注意力层上训练L-FFN,会比(1)放开注意力层,(2)先文本预训练,再冻住注意力层,训练V-FFN,效果更好。与ViLT的想法相似
BLIP(来自ALBEF团队)
- Motivation:
- 目前存在单一使用encoder,但encoder无法做生成;但encoder-decoder方法,并不能很好应用检索任务
- 训练数据集noisy很大,图文对不一定十分匹配 → Caption+Filter来清洗数据
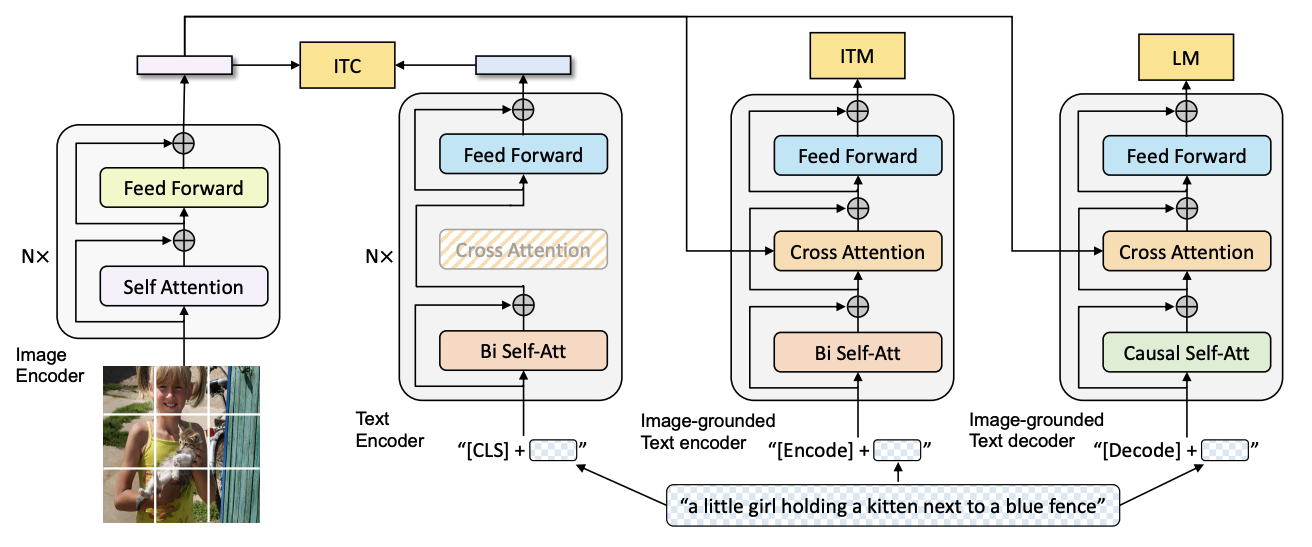
- 模型架构:
- 分别存在三个文本模型,左边两个为encoder,右边一个为decoder,颜色相同部分为共享参数
- ITC,ITM沿用ALBEF中的思路,LM是预测“下一个词”,而非预测“mask掉的词”
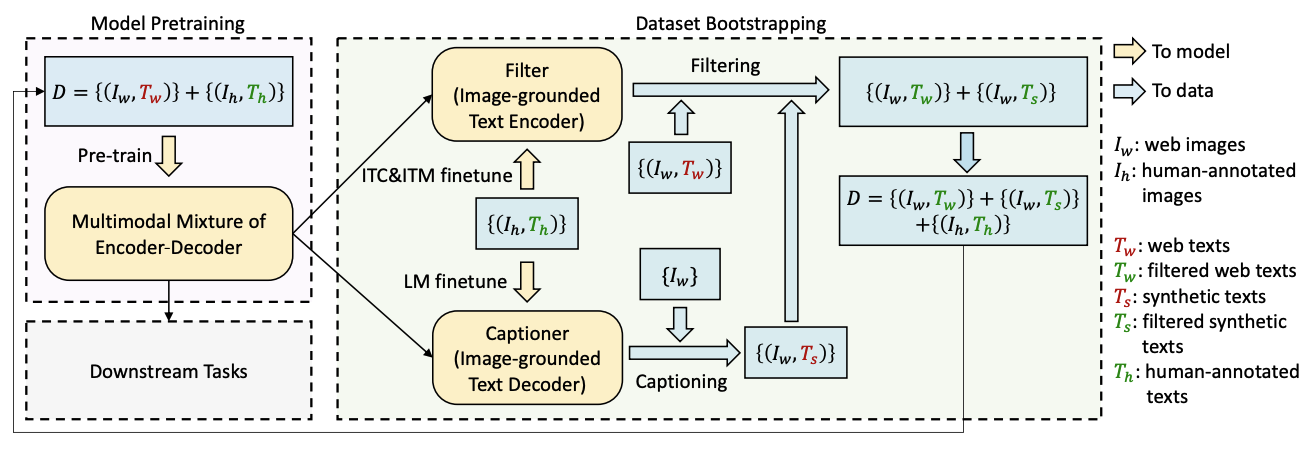
- 数据清洗:
- 首先用有噪声的数据集预训练一个BLIP,再根据精心标注的数据集(CoCo),对三个模块进行微调。
- 对有噪声数据集里面的图文对计算ITM,如果分数较低的话,就利用Captioner重新生成一个标注,从而提高数据集的关联度。
- 利用清洗好的数据集重新训练
BLIP2
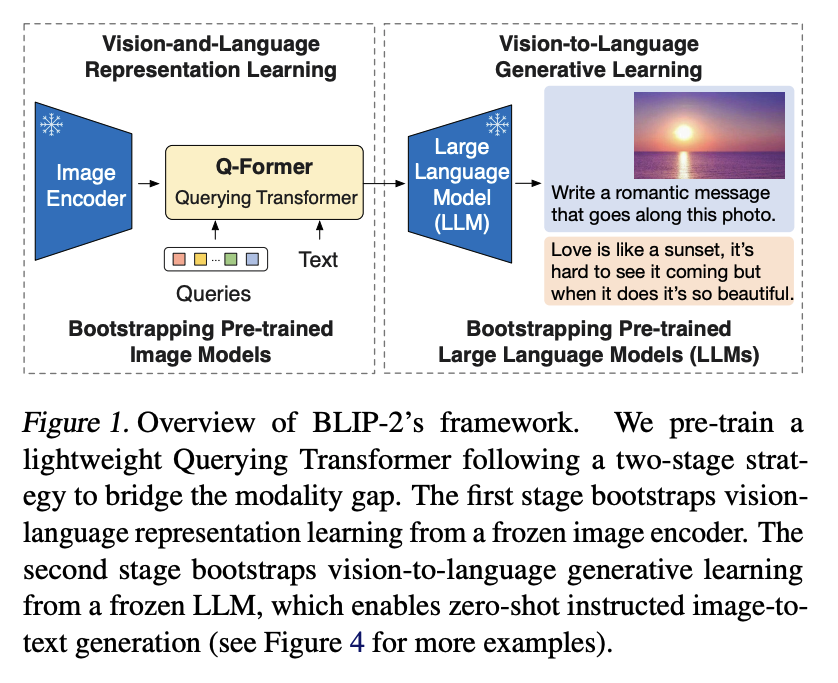
- Motivation:原始BLIP的训练参数太多了,不够lightweight
- Solution:利用一个Q-former充当已训练好的Image encoder和LLM之间的桥梁,将融合了图片信息的文本text feature输入给LLM做后续的下游工作(主要为VQA,Image Captioning,Image-Text Retrieval)
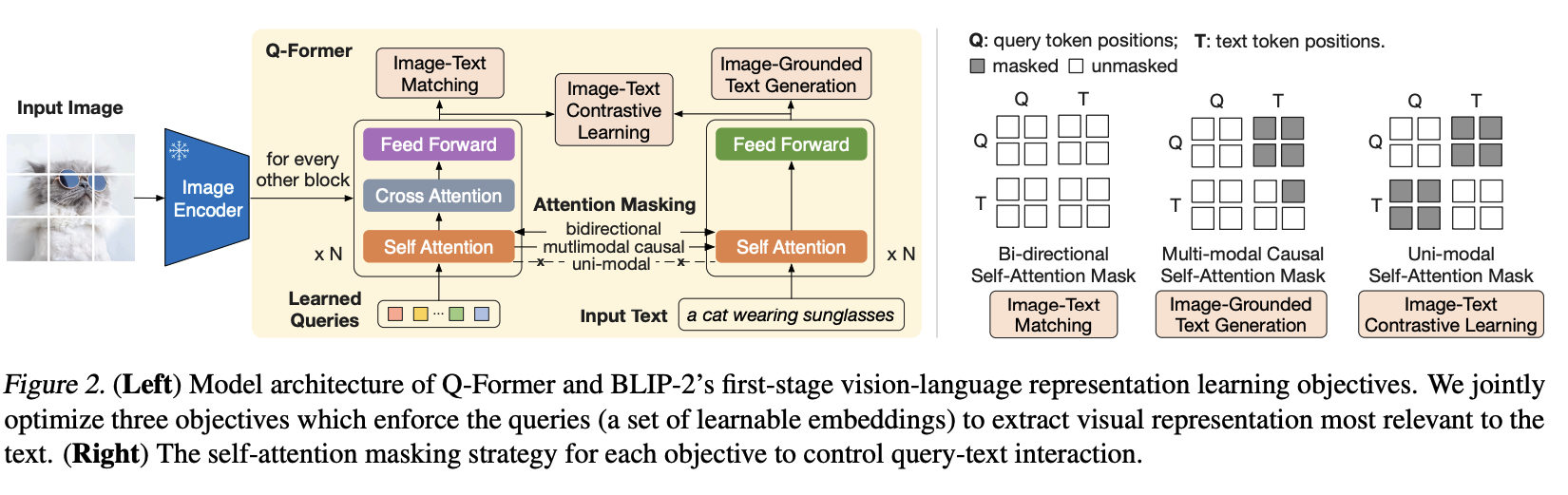
- Q-former训练:ITC,ITM,IGT,由于self-Attention共享参数,不同任务之间的mask要注意。本质上Q-former输出的是融合了图片以及文本的信息。但与后面的LLM的特征空间仍旧不一致。
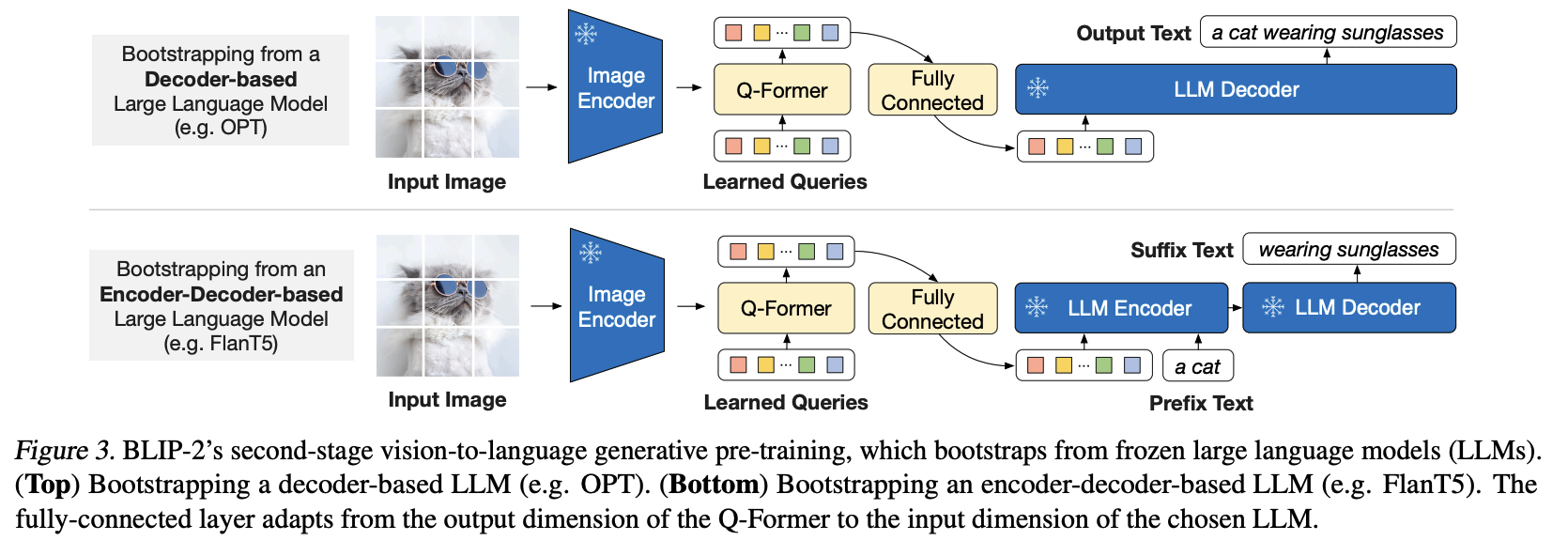
- Q-former中给出的feature,已经融合了指令以及图片的信息。利用LLM的输出,将这个feature (1)对其到文本中,(2)符合groundtruth的输出
CoCa
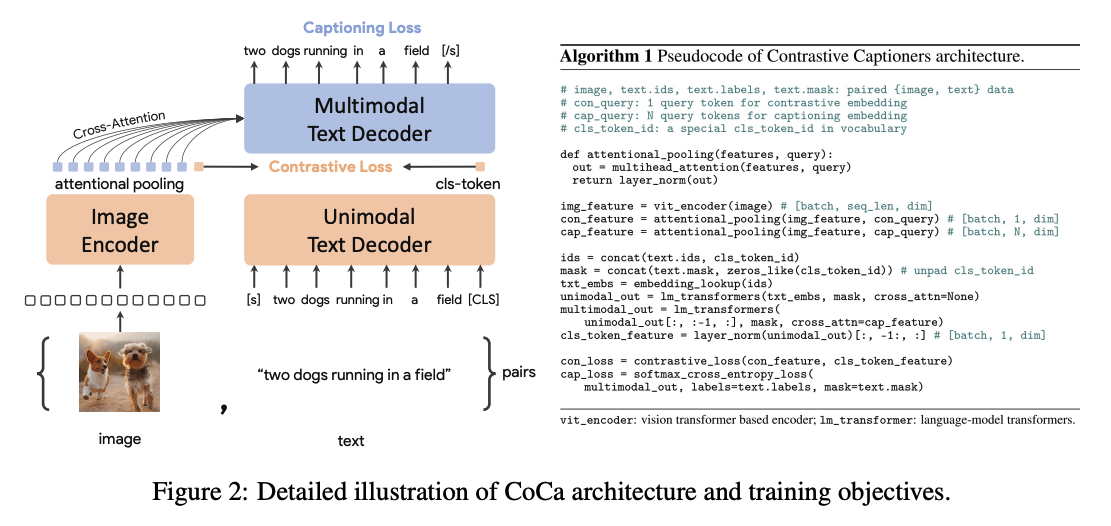
- 文本部分采用Decoder形式
- 训练loss主要是ITC和LM
BEiT v3 (来自VLMo团队)
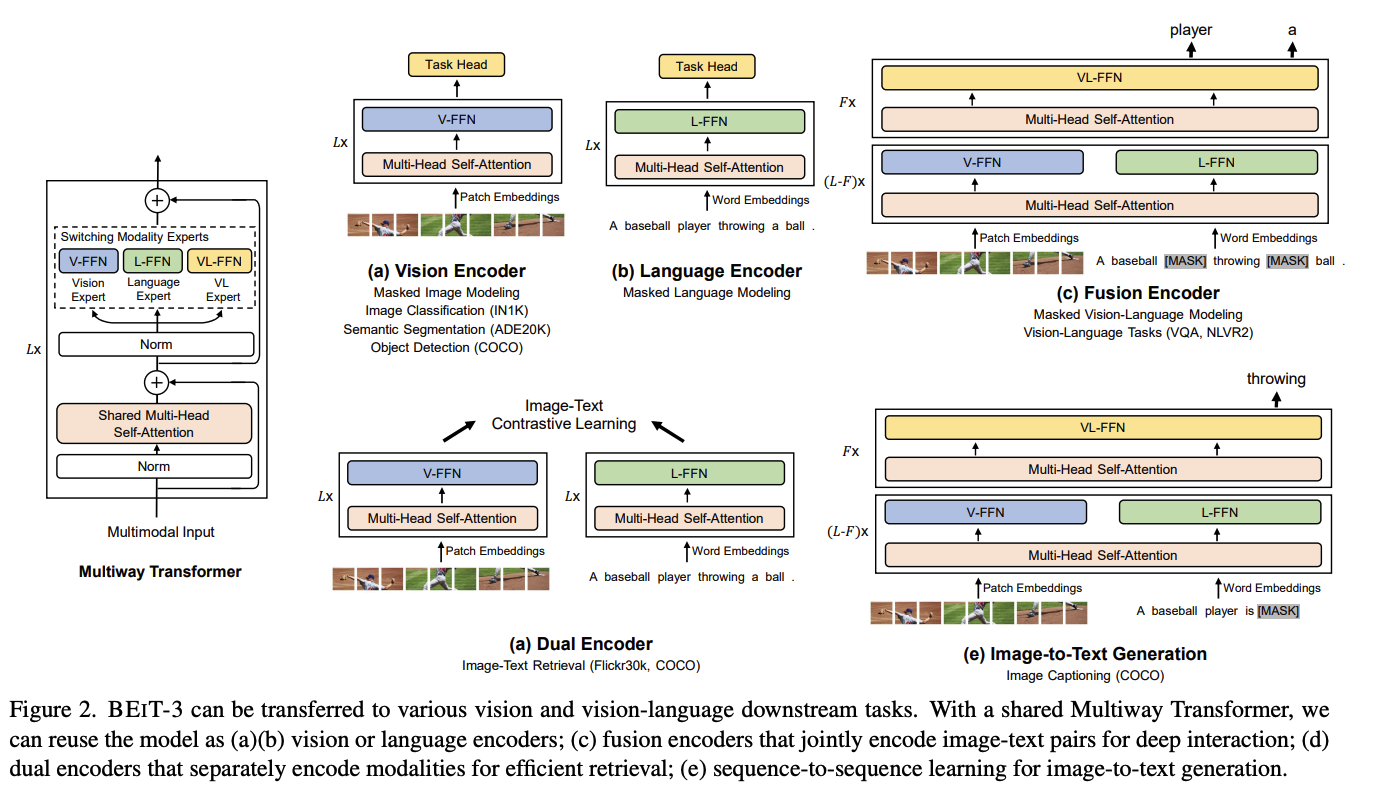
整体架构延用VLMo提出的MoE思路,不同的是,为了降低模型前向forward的次数,BEiT v3放弃了ITC,ITM等其他loss,仅用了”mask-then-predict”方式:
对于L-FFN,利用MLM
对于V-FFN,利用MIM
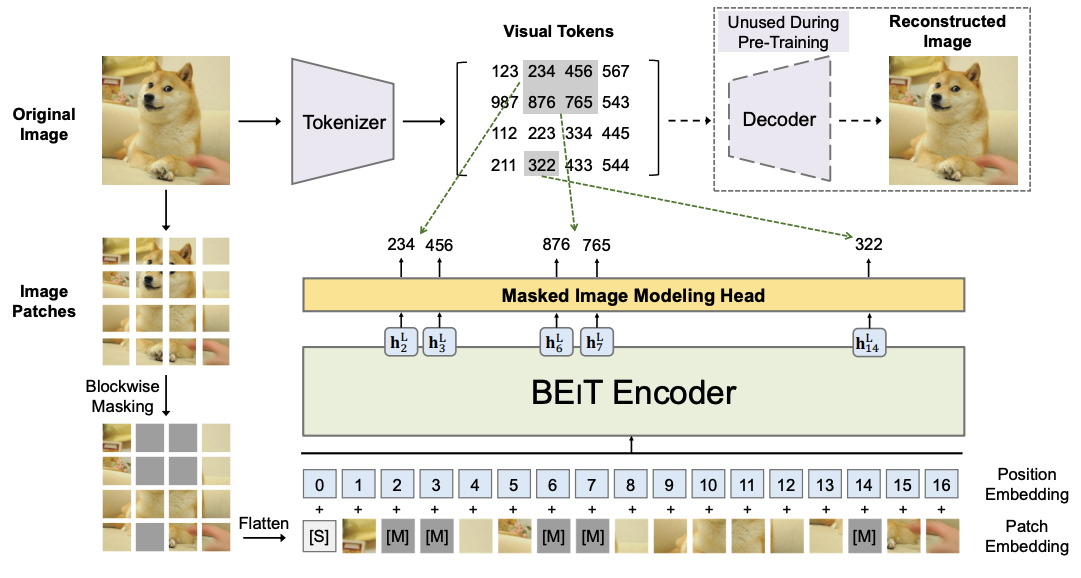
具体MIM方法可参考BEiT:
对于VL-FFN,则融合使用MLM和MIM
作者指出,通过简单的pretrainng task,BEiT v3提高了模型scaling-up的能力,相比于CoCa 65k batchsize,CLIP 32k batchsize,BEiT v3仅需要6k batch size就能达到更好的效果。
Object Detection and Segmentation
DETR
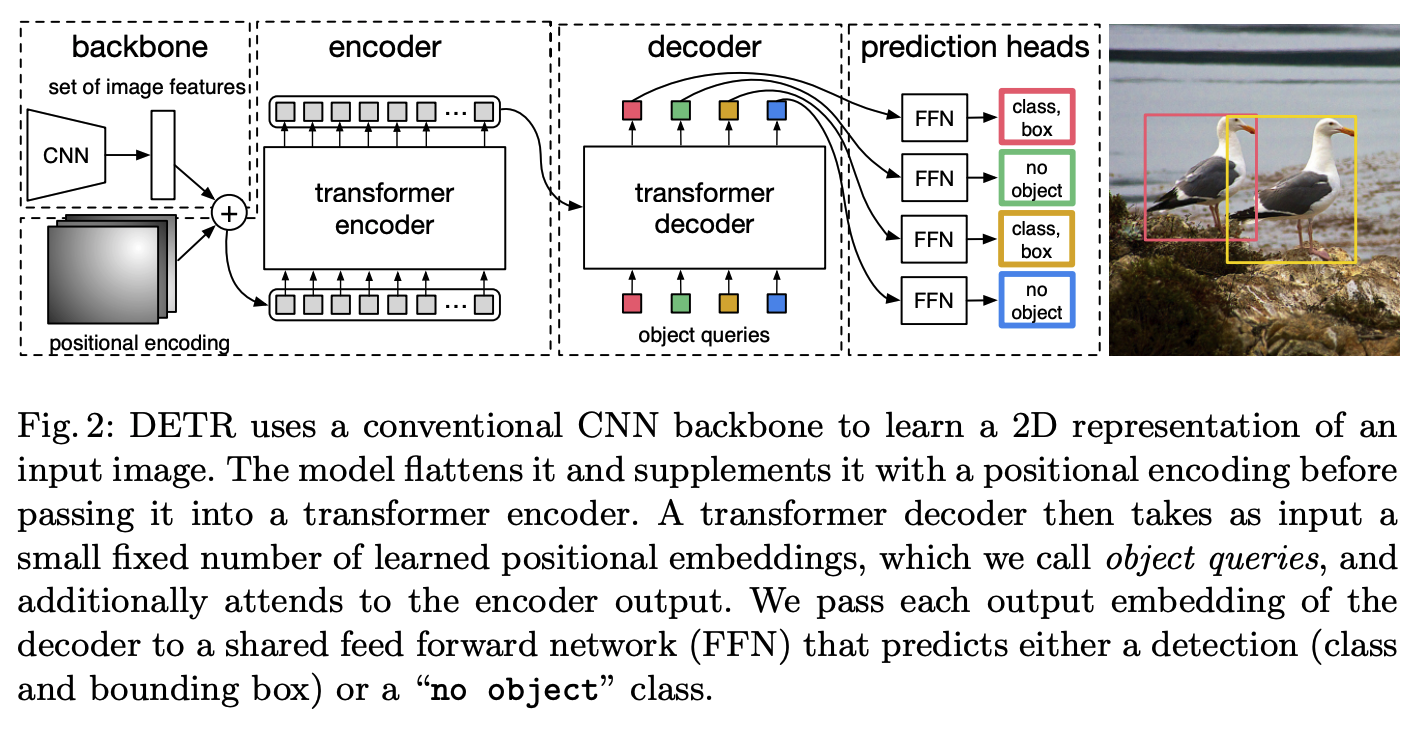
Transformer固定出100个框,利用二分图匹配,与GT比较,仅用与GT最相近的框进行loss计算,其余被归类为no object。解决了先前工作中同一个物体出多个框的问题。
伪代码:

[CVPR 2024] DINOv:Visual In-Context Prompting
https://github.com/UX-Decoder/DINOv
写作太烂了!!!!根本看不下去,建议作者回炉重新学习论文写作
新概念
- In-context prompting:通过输入在LLM的上下文中直接给出提示,而非通过训练或微调。其中,few-shot,one-shot是in-context prompting的特殊方式。任何在输入上下文(文本/视觉)中给的提示,包括指令、示例、标签、视觉线索等,均可以算做广义的in-context learning。
- Referring Segmentation(指代分割):从图像中分割出用户指定的唯一目标
- 语言提示:the dog on the left
- 视觉提示:在图像上点击、画框、涂鸦,明确指向哪个目标
- Open-set Segmentation(开放集分割):分割图像中所有符合语义的对象,包括训练时未出现过的新类别
- Motivation:
- 目前visual in-context learning仅将用户视觉提示与最相关的单个对象关联,在识别多个具有相同语义概念的对象方面能力有限。
- textual prompting不适合于提供视觉的in-context指导
- 之前的视觉 in-context 工作大多局限于指代分割,缺少一个能同时处理通用分割与指代分割的统一模型。
- DINOv支持generic以及referring分割,同时支持多样化的visual prompt输入
- 希望做一个大一统的工作
[ECCV2024] PartGLEE: A Foundation Model for Recognizing and Parsing Any Objects
https://github.com/ProvenceStar/PartGLEE
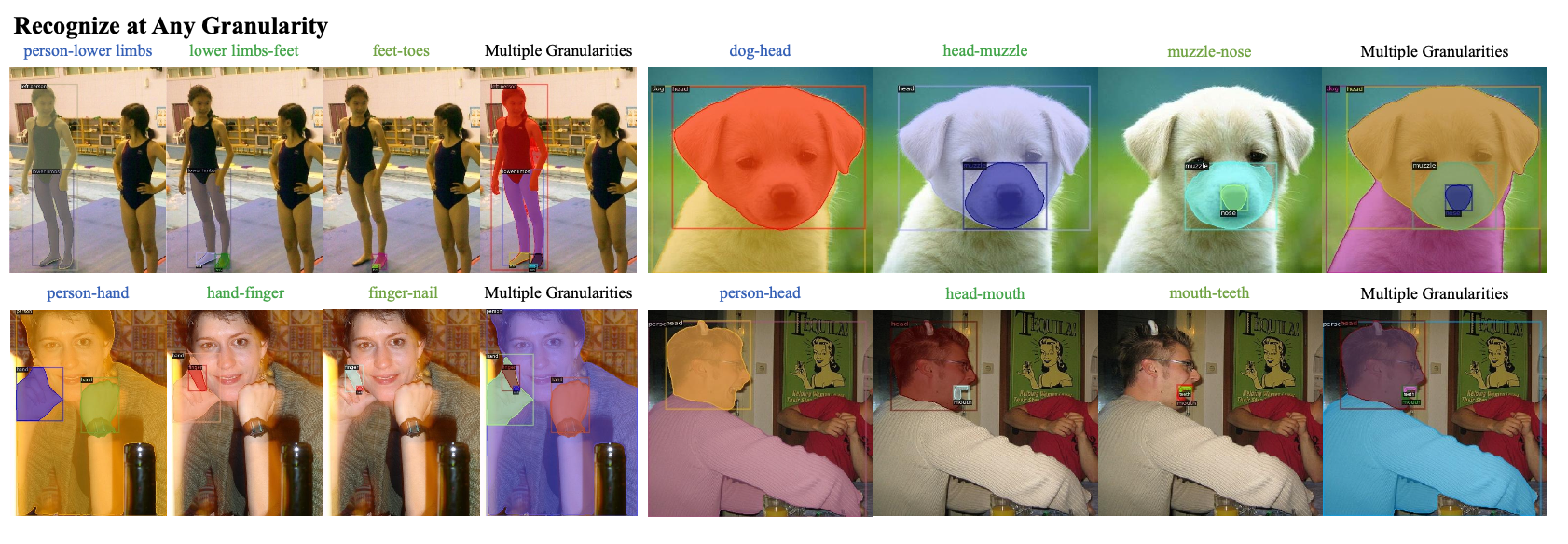
PartGLEE旨在弥补现如今分割任务中,颗粒度不细致的问题。PartGLEE通过hierarchical方法,能够准确识别细粒度的物体分割任务。
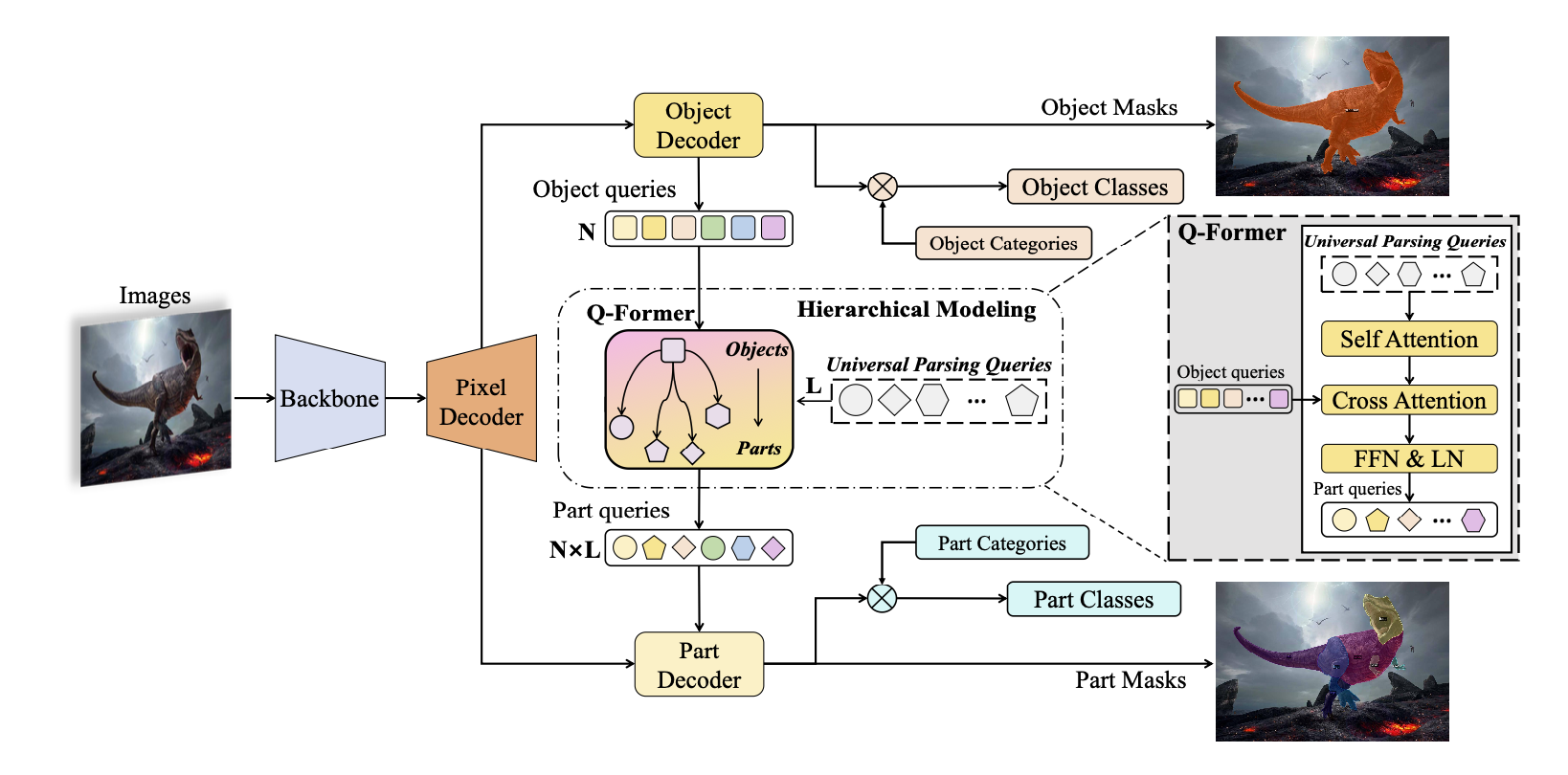
解决细粒度的方法
- 粗筛:在Q-former中预先设计好L个Universal Parsing Queries,这些queries可能是所有object中所共有的一些局部特征。Object Decoder输出N个object的queries向量,每一个object均需要和L个universal parsing queries进行计算,最终得到N*L个局部特征queries。
- 细筛:利用CLIP的text- encoder对有所类别(object和part)输出text feature,并与object queries和part queries进行相似度计算,后续通过约束进行训练。
实验
We utilize object-level datasets such as COCO [38], LVIS [16], Object365 [65], OpenImages [26], Visual Genome [25] and RefCOCO series [47,91], etc, while using part-level datasets PACO [59], PartImageNet [18], Pascal Part [6], ADE20K-Part [75] and SA-1B [24] with varying annotation granularity for joint-training.
在32张A100中进行大乱炖
[24.1] Grounded SAM: Assembling Open-World Models for Diverse Visual Tasks
主要idea是利用G-DINO + SAM做下游任务
- SAM:对任意图像生成mask,但需要提供points,boxes,text当作prompt
- Grounding-DINO:open-set object detection模型,但需要text input,同时只能生成box
- OSX:全身网格恢复模型,从单目图像中估计人体SMPL。需要检测人体框,随后对这些人体框进行裁剪与缩放,最后对单人进行网格恢复处理。
- BLIP:用它的captioner,对图片生成description。但不能做object detecting或者segmenting
- RAM:图像标注模型,能够对输入图像中常见类别进行高精度识别和标注。但RAM 只能生成标签,无法为识别出的类别生成精确的边框和掩码。
- Diffusion:文字生成图片
- GPT:大语言模型
两两结合做实际工程上任务
[CVPR 2025] DINOv2 Meets Text: A Unified Framework for Image- and Pixel-Level Vision-Language Alignment
- Motivation:
- CLIP的训练方式很好,但它需要同时对文本,视觉编码器从头训练。
- 固定一个模态的encoder,只对另外一个encoder进行对齐,理论上应该是可行的,但目前为止的试验结果是不理想的。
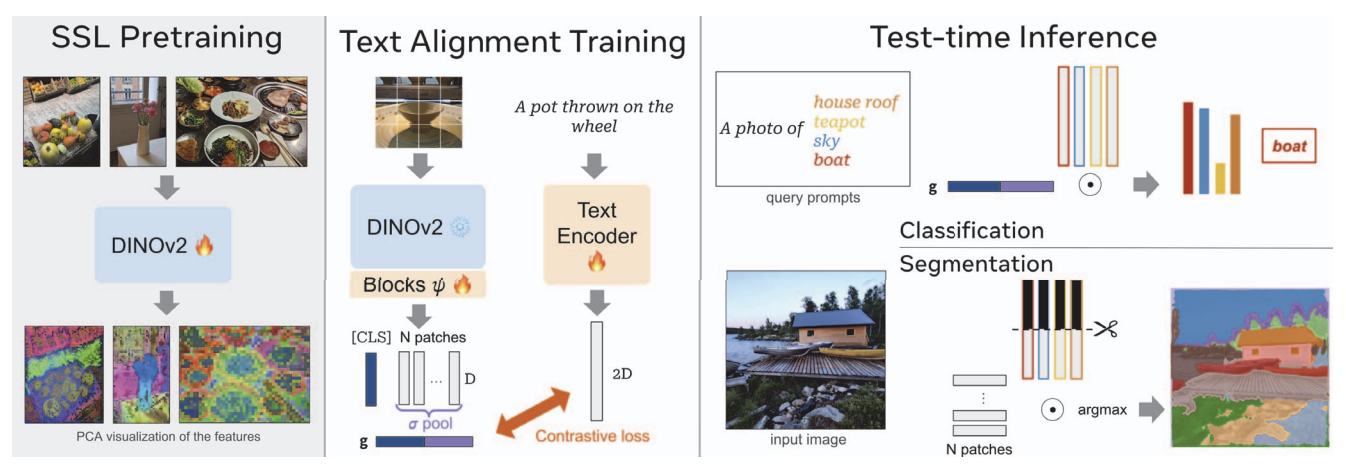
- Solution:
- 与其利用[CLS]代替整个图片的feature,利用average pooling,将所有patch的feature进行融合
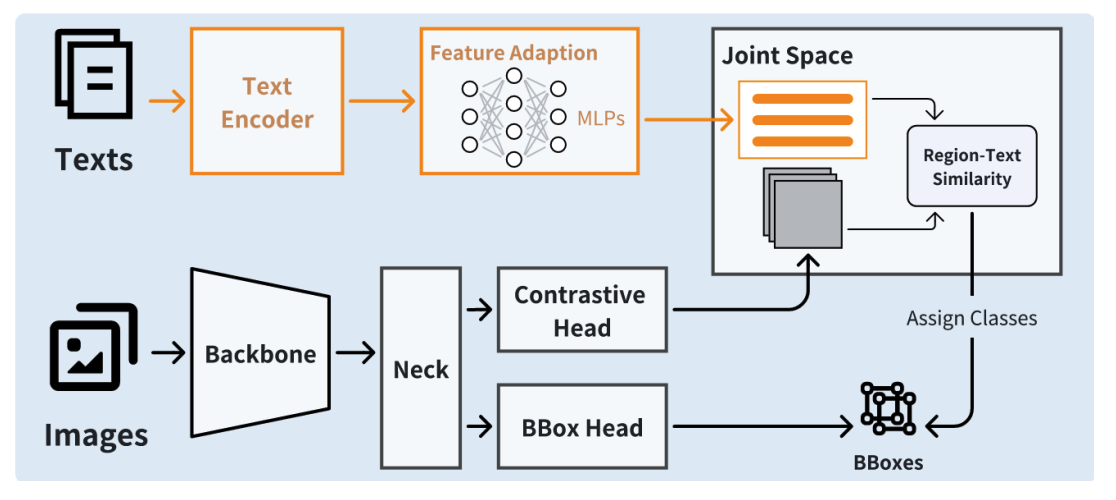
[24.12] A Light-Weight Framework for Open-Set Object Detection with Decoupled Feature Alignment in Joint Space
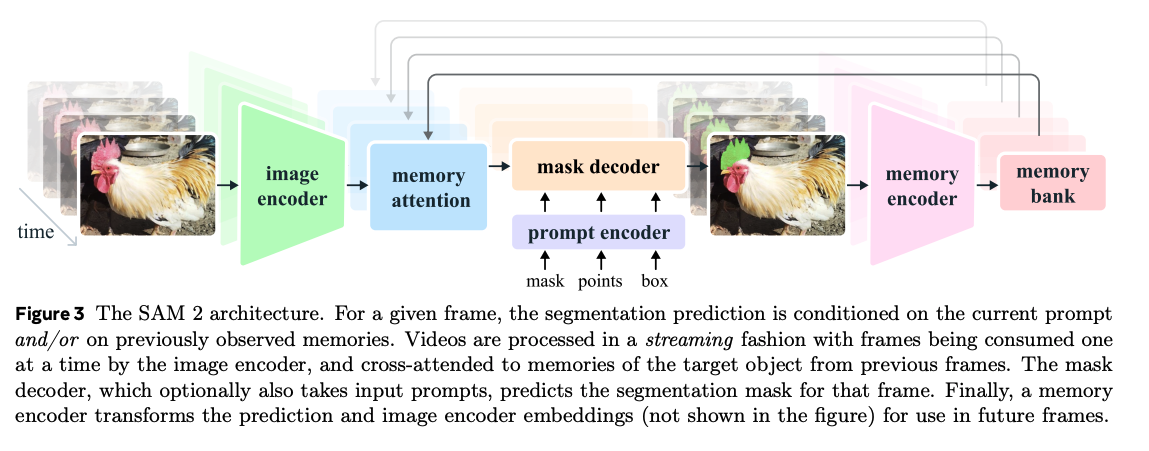
[24.10] SAM 2: Segment Anything in Images and Videos
https://github.com/facebookresearch/sam2
[CVPR 2024] PixelLM: Pixel Reasoning with Large Multimodal Model
https://github.com/MaverickRen/PixelLM
- PixelLM功能:依据图片以及文本提示,对图片进行segmentation,同时可以输出文本进行图片理解
- Contribution:
- pixel-level mask
- multiple open -world target

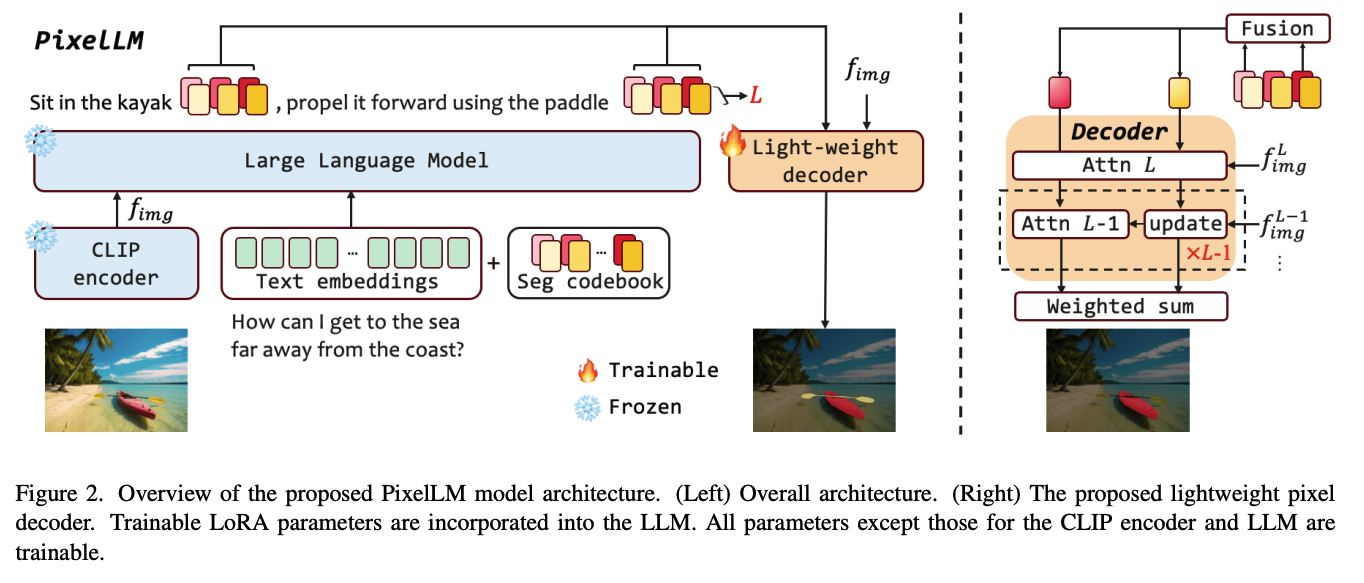
- Contribution:
- Seg codebook:多尺度,多token,蕴含目标mask信息的feature
- Light-weight Decoder:将codebook feature以及image feature转化为mask
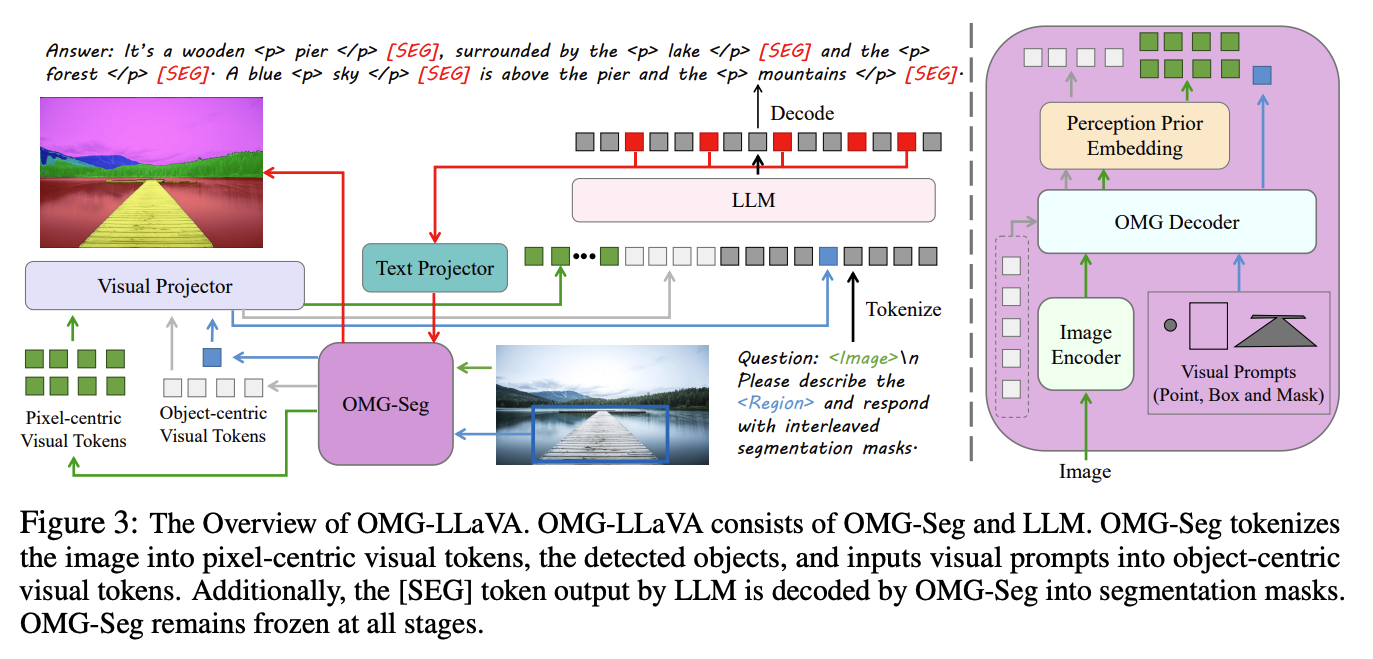
[CVPR 2024] OMG-LLaVA: Bridging Image-level, Object-level, Pixel-level Reasoning and Understanding
https://github.com/lxtGH/OMG-Seg
- Motivation:做一个unified model来同时handle image-level (such as image caption and image-based conversation), object-level (such as region caption and visual prompt-based conversation), and pixel-level (such as universal segmentation, referring segmentation, reasoning segmentation, and grounded conversation generation)
[2025.06] Seg-Zero: Reasoning-Chain Guided Segmentation via Cognitive Reinforcement
https://github.com/dvlab-research/Seg-Zero
- Motivation: out-of-domain generalization
- Task: Reasoning Segmentation(i.e. 提供描述性文字,模型输出相应图片描述,以及对应对象的semantic mask)
- 摒弃LISA提出的
字段
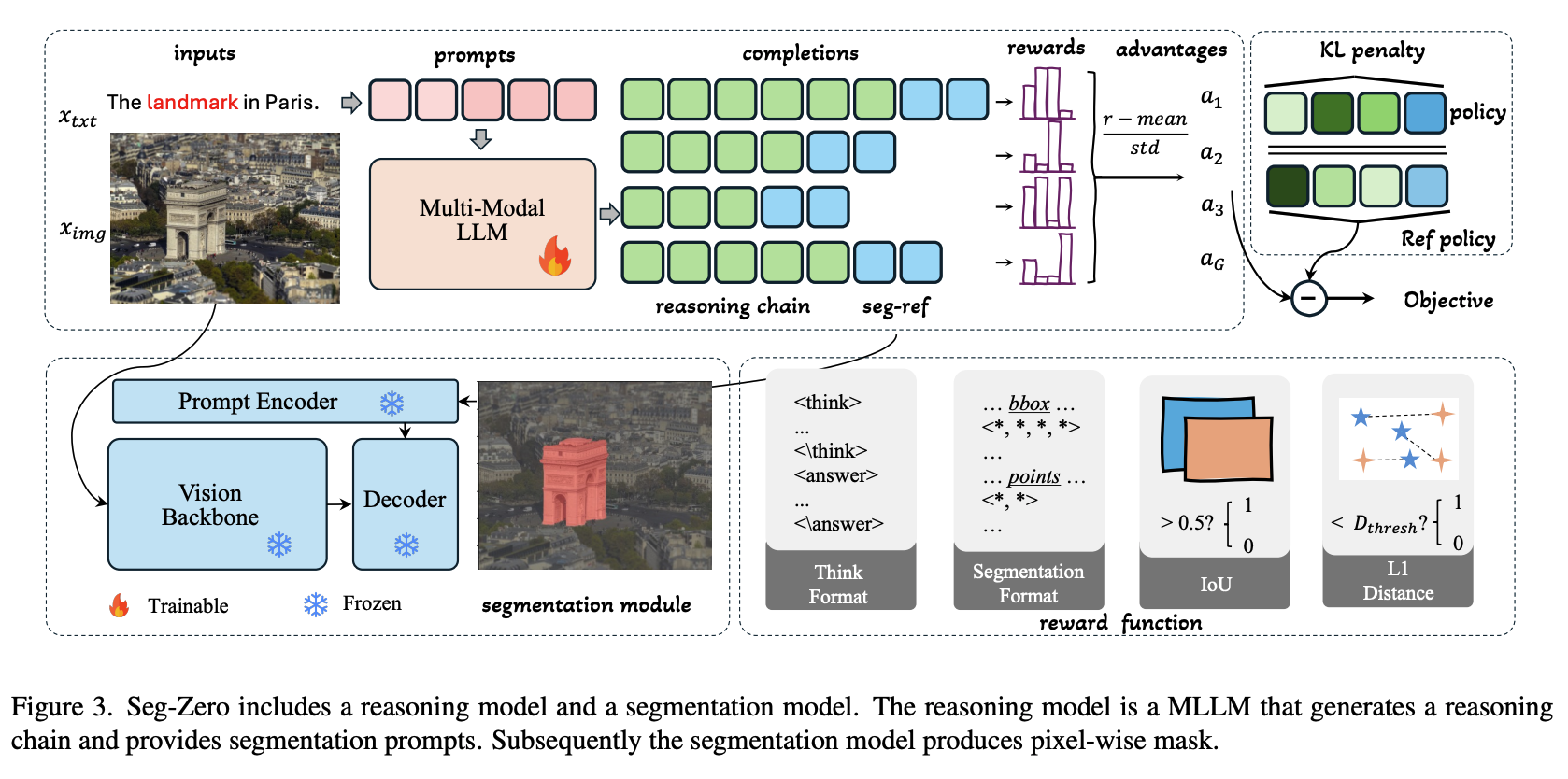
- 架构:
- MLLM采用Qwen2.5-VL,输入图片以及文本,输出CoT回复+bounding box和可以描述对象的点P1,P2
- 将box和P1,P2当作visual prompt输入到Mask Decoder(SAM2)中,生成相应的semantic mask
亮点1: GRPO训练方法
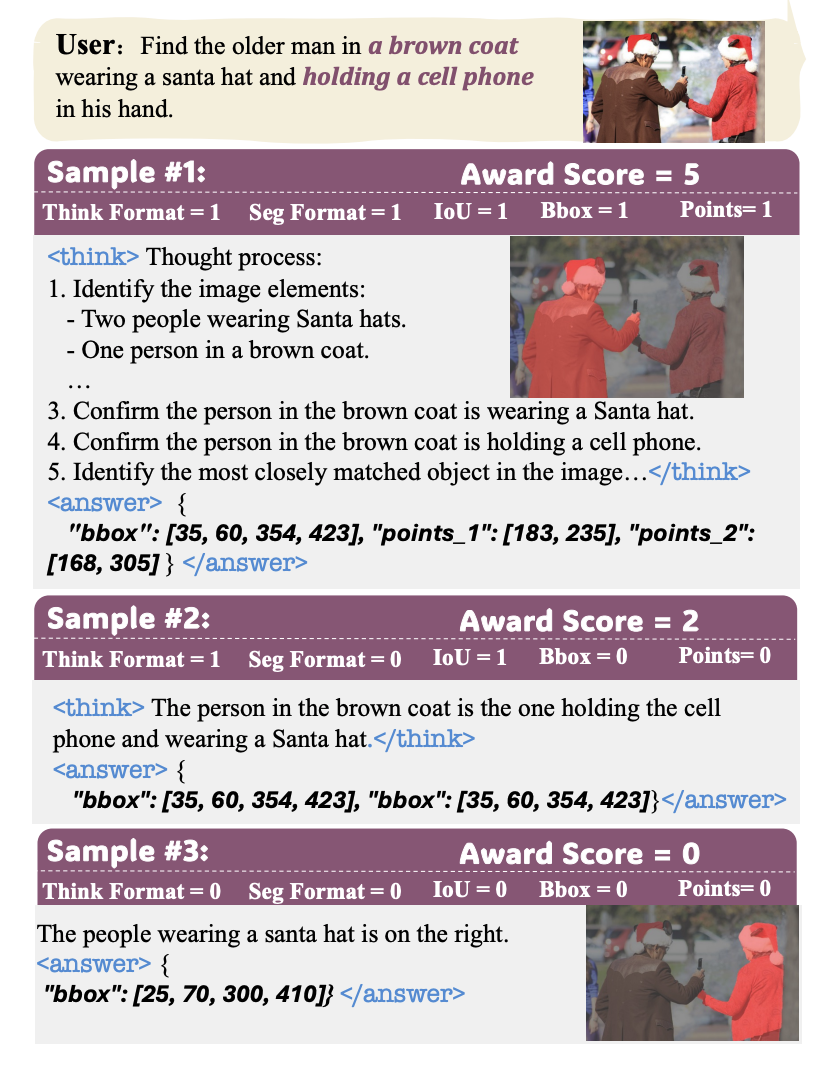
亮点2: CoT from zero(并没有构建具有CoT回复的label,在prompt中引导MLLM进行CoT回复)整体训练完全为RL训练

[2025.04] Pixel-SAIL: Single Transformer For Pixel-Grounded Understanding
暂无代码(2025.8.12)
- Motivation:用一个Transformer模型去完成Referring Segmentation以及Referring Expression任务
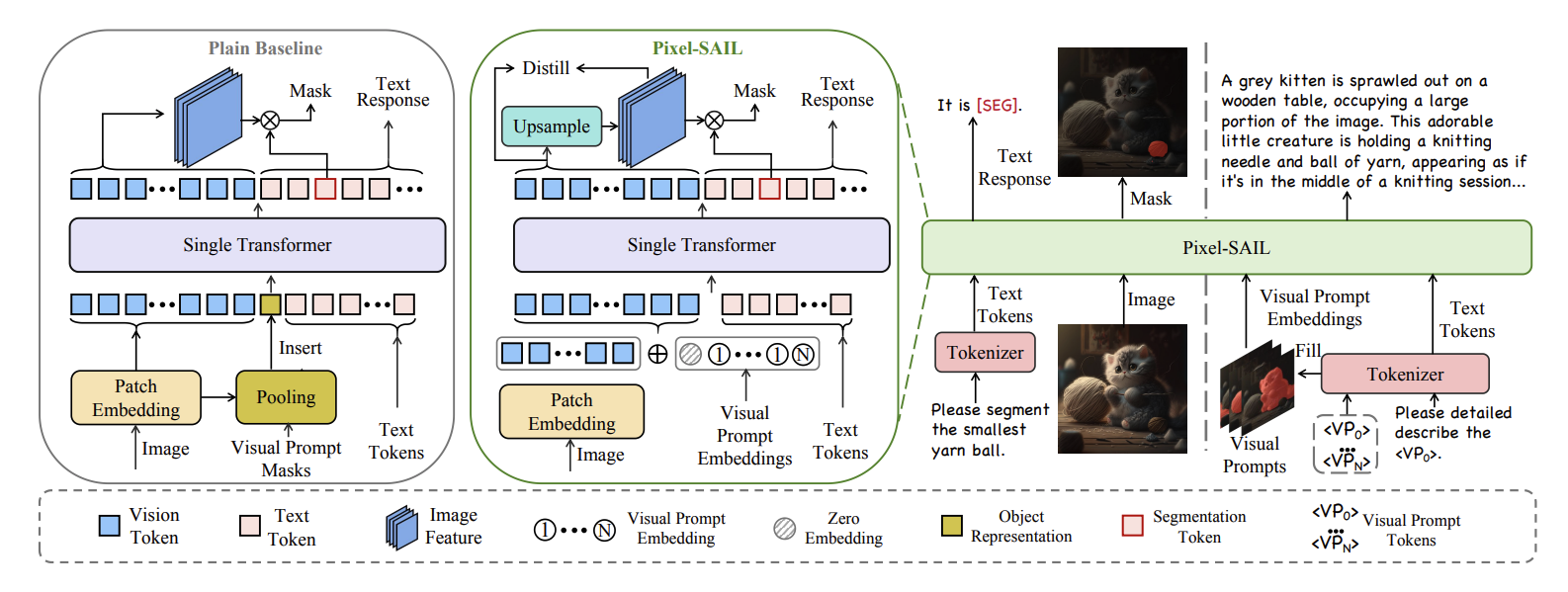
- Contribution:
- Learnable Up-sampling Module:假设图片经过Transformer输出的大小为$\mathcal{V} \in \mathbb{R}^{N \times C}$,将其调整为image feature $\mathcal{F} \in \mathbb{R}^{\frac{H}{S} \times \frac{W}{S} \times C}$ ,通过here的方法将其up sampling为$\mathbb{R}^{\frac{H}{4} \times \frac{W}{4} \times C}$ ,并与Transformer中的predicted segmentation token,shape为$\mathcal{Q} \in \mathbb{R}^{K \times C}$ 进行矩阵相乘,得到segmentation mask $\mathcal{M}\in \mathbb{R}^{K \times\frac{H}{4} \times \frac{W}{4}}$
- Visual Prompt Injection: 没看懂…,大体上给出一种在Referring Expression任务中对visual prompt的parameter free的encoding 方法
- Dense Feature Distillation:利用Mask2Former对upsampled mask features,SAM2对low-resolution feature $\mathcal{F_l} \in \mathbb{R}^{\frac{H}{S} \times \frac{W}{S} \times C}$ 进行蒸馏学习
[2025.06] Perceive Anything: Recognize, Explain, Caption, and Segment Anything in Images and Videos
https://github.com/Perceive-Anything/PAM
文章在intro部分详细对visual prompt编码的方式进行了总结,后期可以考虑深入阅读
Motivation:
先前工作呈现出以下局限性仅生成有限的语义输出——往往只是类别标签或简短的描述
聚焦于单一视觉模态(图像或视频)
依赖外部分割模型来提供掩mask,这种串行设计增加了计算开销,并使整体性能对mask质量敏感
Multi-Task Fulfillment:
在给定一张图片以及visual prompt之后,PAM可以
- 分割(Segment):为图像或整个视频中指定的区域生成精确的分割掩码。
- 识别(Recognize):识别指定区域或目标的类别。
- 解释(Explain):在给定上下文中,对该区域或目标的定义、属性及功能进行清晰解释。
- 描述(Caption):为图像、视频及视频流中的该区域生成简洁或详细的文字描述
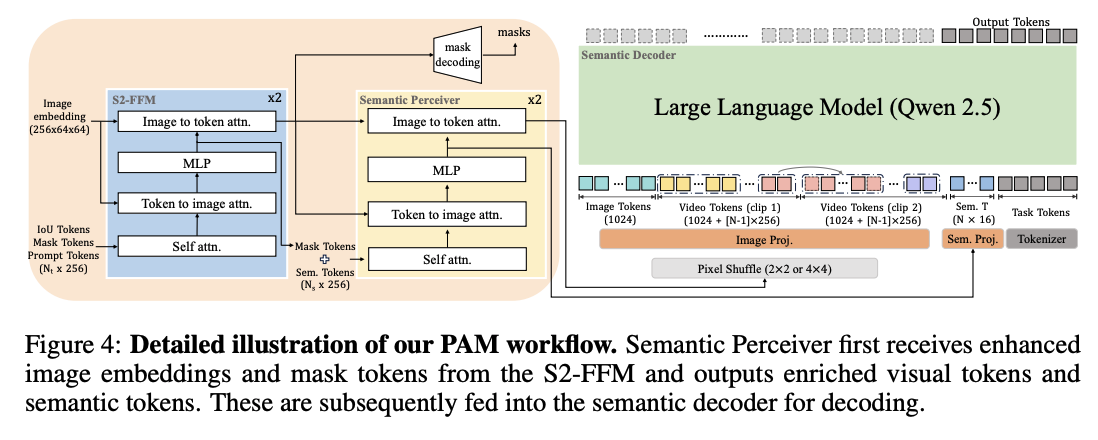
通过利用SAM2的丰富语义信息,通过Semantic Perceiver充当桥梁,将SAM2的语义信息传递到LLM中,进行后续任务的生成
Grounding-MLLM
[23.07] KOSMOS-2: Grounding Multimodel Large Language Models to the World
https://github.com/microsoft/unilm/blob/master/kosmos-2/README.md
卖点:具备感知目标描述(如边界框)以及将文本锚定到视觉世界的新能力 →
人话:可以通过box或者语言描述让MLLM理解图片中的物体位置信息;同时MLLM可以根据语言描述/box框选定位图片中对应的object,并以此做出回答

Contribution 1:GRIT Dataset
GRIT数据集的生成与LLaVa的instruction生成类似,均是使用成熟工具将已有数据集加工成符合任务需求的版本。
spaCy进行名词提取 + GLIP出框 + spaCy进行名词扩展

- Contribution 2:KOSMOS-2
- Grounded Input
- Transformer-based causal language model + the next-token prediction task
[24.04] Ferret-v2: An Improved Baseline for Referring and Grounding with Large Language Models
- Motivation:
- 现如今vision encoder只能对固定分辨率图片进行编码,且分辨率太小
- 对于细粒度的referring和grounding问题表现不佳
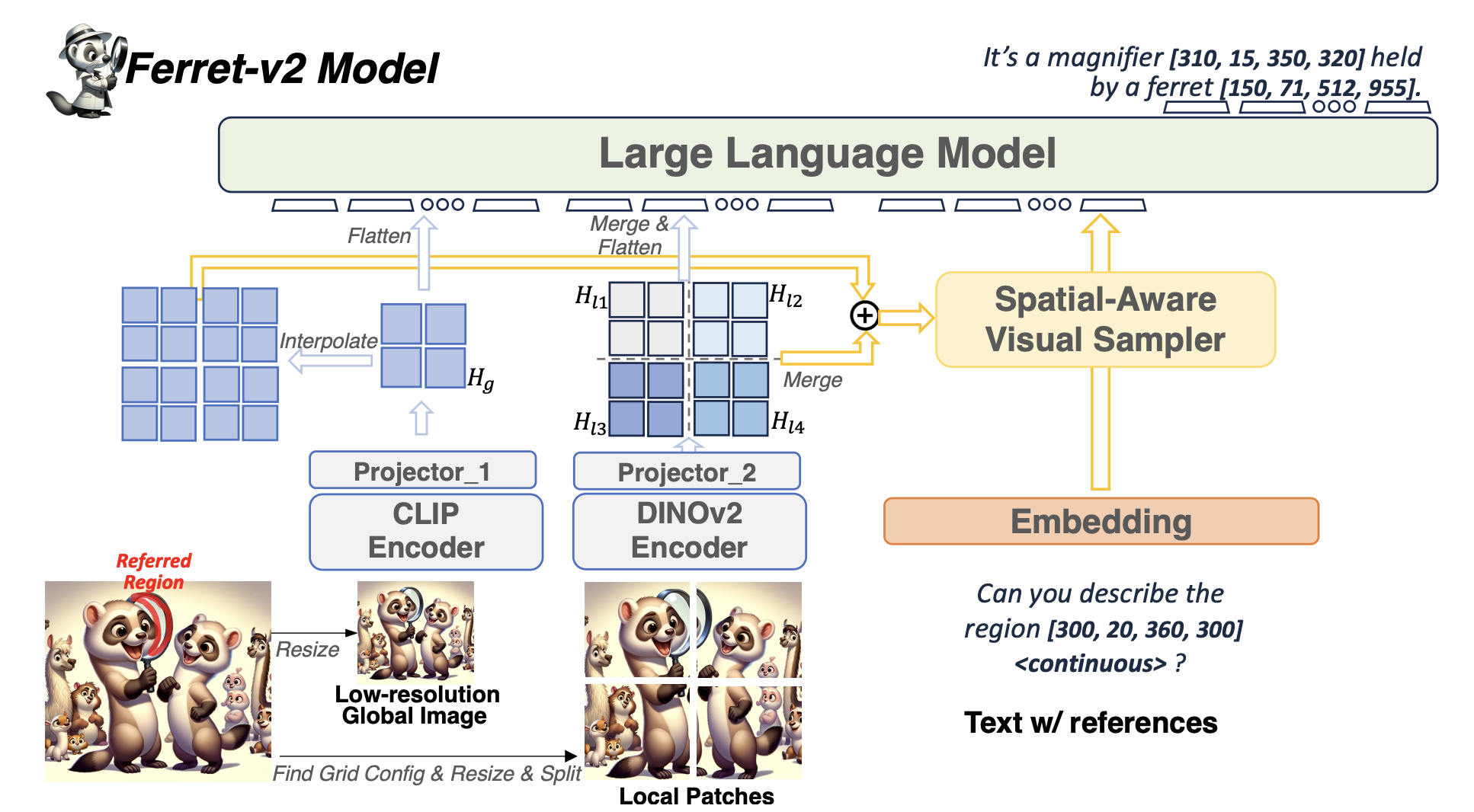
- Solution:
- 两个vision encoder,CLIP encode global images,DINOv2 encode local split patches.
- 将任意分辨率图片打成patch,分批送入DINOv2中
- Ferret-2也有一个GRIT数据集
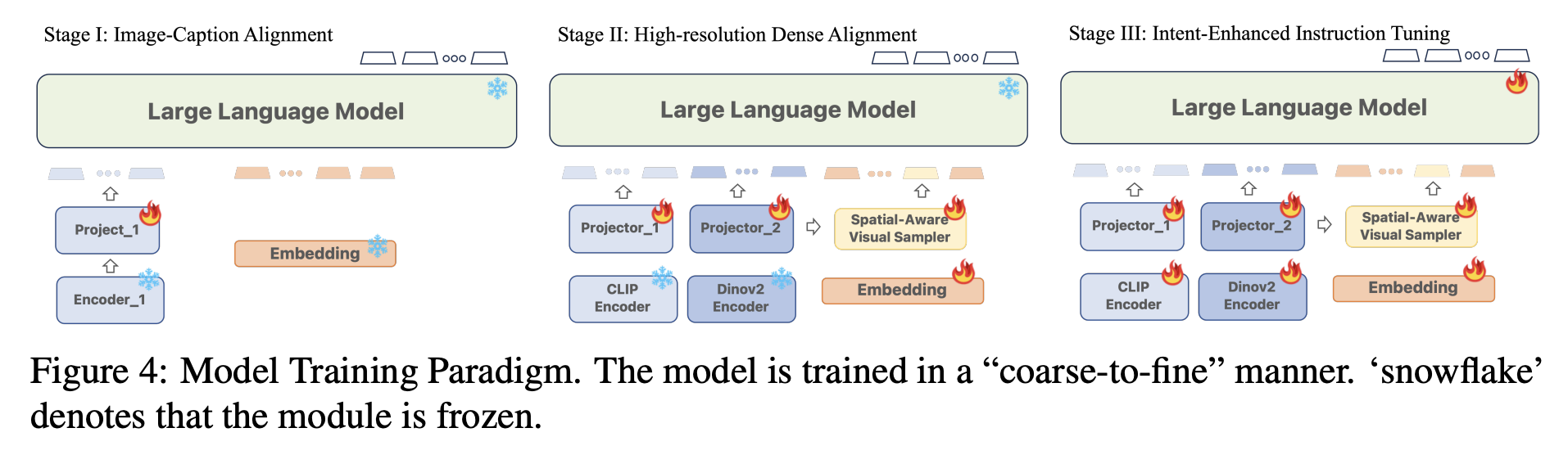
- Training:
- 阶段1:只训练将CLIP投影到LLM维度的project层
- 阶段2:DINOv2的project层与CLIP的共享初始参数,通过Dense referring and detection训练除去encoder和LLM的所有参数
- 阶段3:用全部数据训练所有参数,同时用LLaVa的数据集做指令微调
[ECCV 2024] Groma: Localized Visual Tokenization for Grounding Multimodal Large Language Models
Groma: Localized Visual Tokenization for Grounding Multimodal Large Language Models
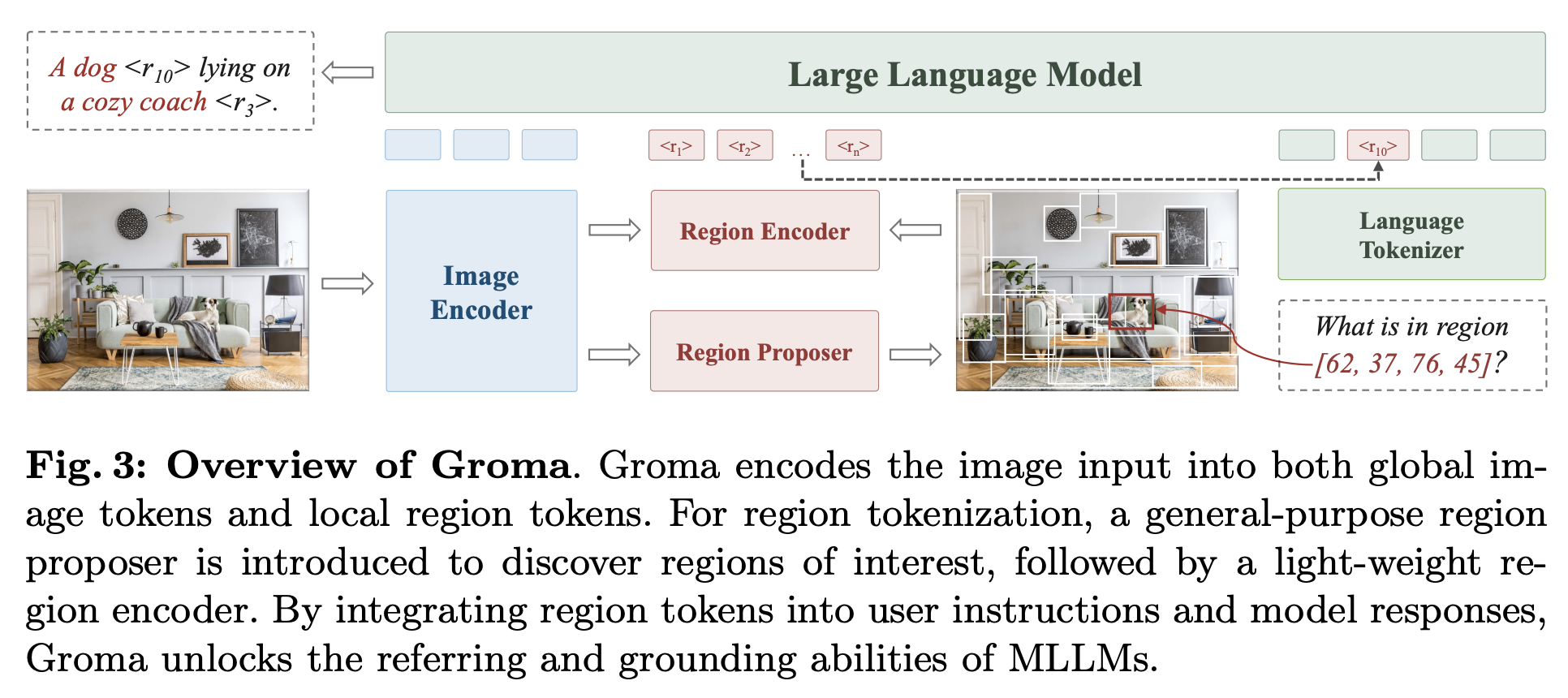
架构:
Image Encoder:DINOv2
Region Proposer:DDETR,承接DINOv2的feature,给出图片的object detection box
Region Encoder:将image feature和detection box编码成region feature
feature与box一一对应
训练:
- 先训练DDETR的目标检测能力,imgae encoder参数冻住
- vision,region,language对齐,只训练MLP projector和region encoder,其余参数冻住
- 指令微调:自己的grounding数据集 + LLaVa + ShareGPT-4V
[NIPS 2024] SimVG: A Simple Framework for Visual Grounding with Decoupled Multi-modal Fusion
https://github.com/Dmmm1997/SimVG
- Motivation:现如今所有做Visual Grounding任务的模型,在进行模态融合之前,均需要单独对各个模态进行encoding。而模态融合仅依赖少量下游任务数据集,低估了模态间相互理解的难度。
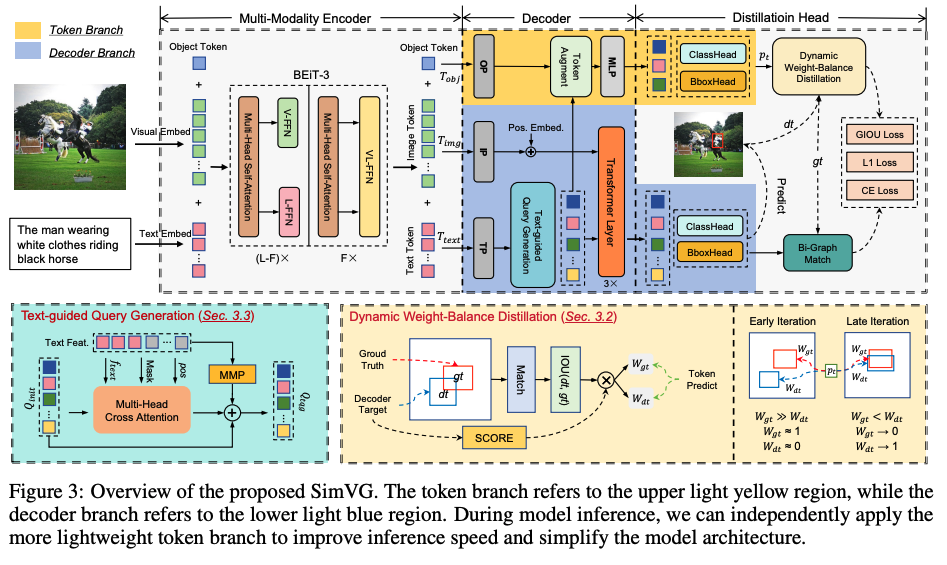
- Solution:
- 利用BEiT-3的架构充当Encoder,实现多模态的融合
- Decoder部分采用DETR架构 → 文字引导的DETR出框工作
- 多了一个object token,用来做最后的box和classification部分。objection token的训练逐渐由ground truth引导到DETR decoder引导
- 缺陷:似乎只能做出框?不能像上述的一些任务,做自然语言的交互
[ICLR 2025] MLLMs Know Where to Look: Training-free Perception of Small Visual Details with Multimodal LLMs
https://github.com/saccharomycetes/mllms_know
- Motivation Example:当图片尺寸逐渐缩小到文本关注的范围时,MLLM正确作答的概率大大增加
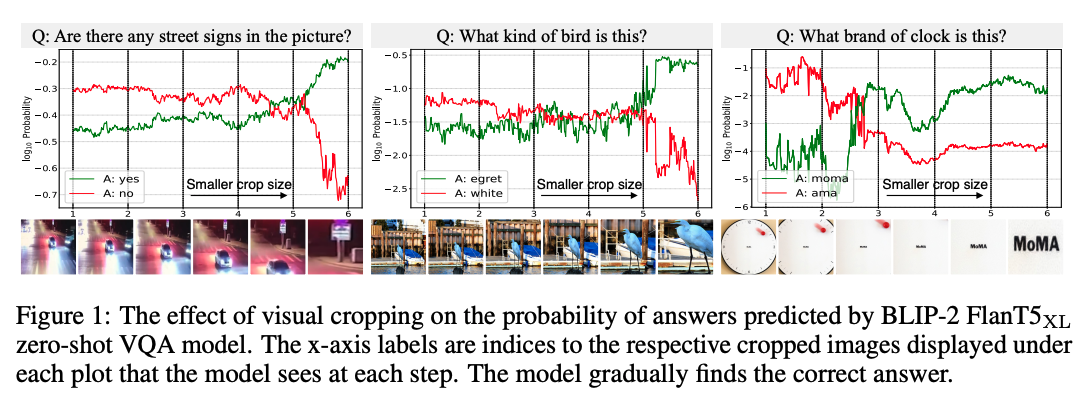
- Solution:实际上注意力机制反映了,当图片与文本align的时候,注意力分数较高,可以通过注意力分数引导图片的crop,然后引导LLM得到更准确的答案
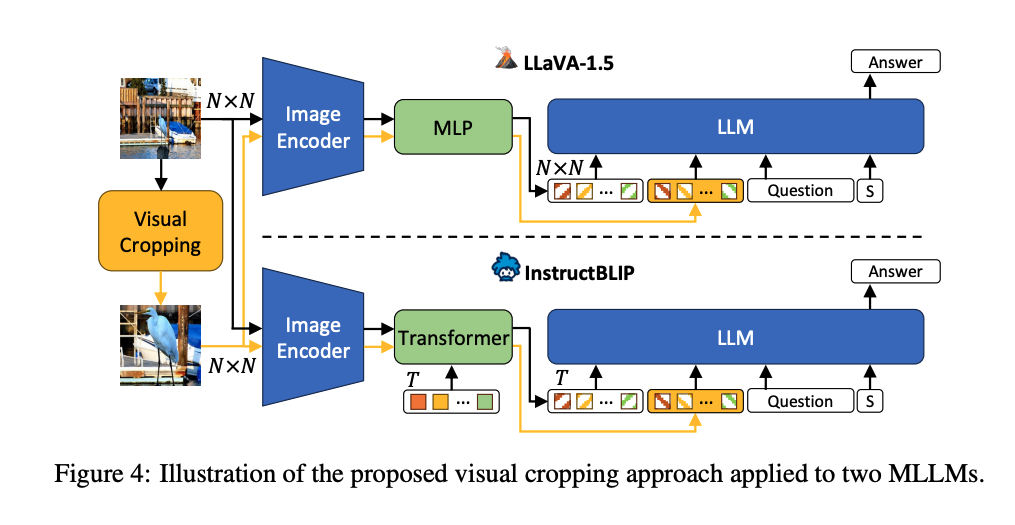
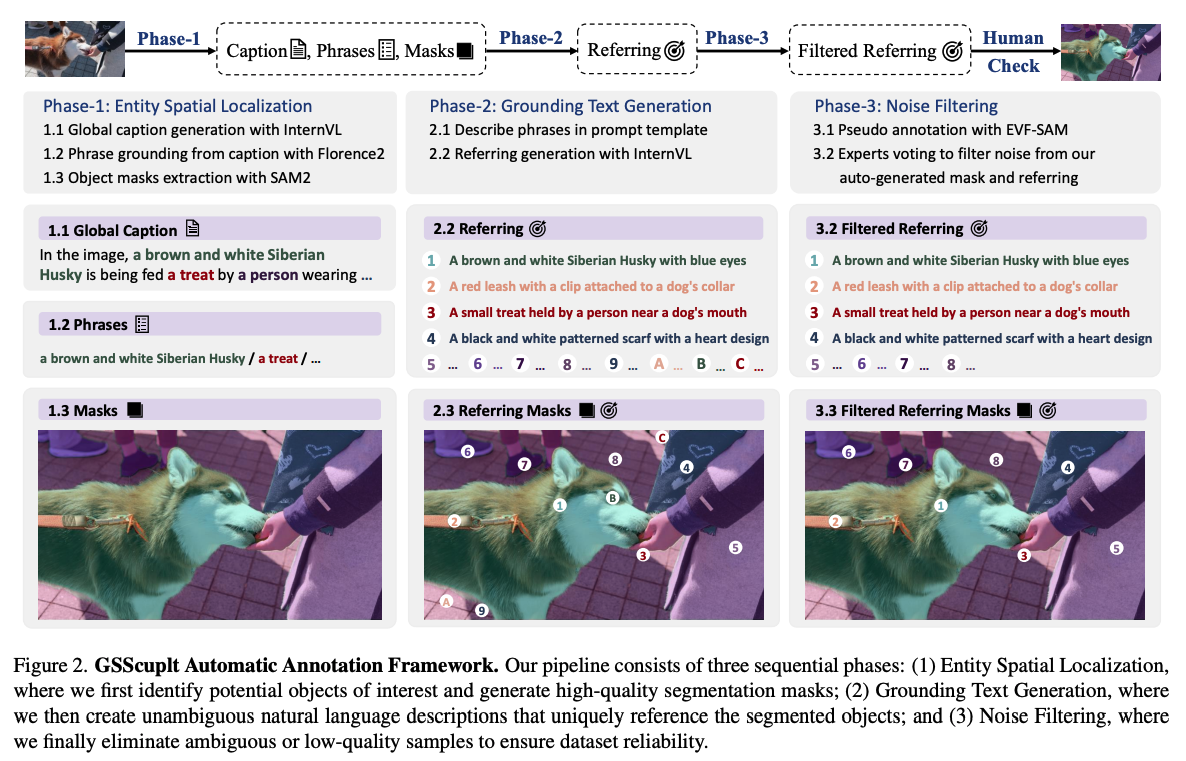
[ICCV 2025] GroundingSuite: Measuring Complex Multi-Granular Pixel Grounding
https://github.com/hustvl/GroundingSuite
- Benchmark工作,贡献包含:
- 利用VLM agent进行自动标注
- a large-scale training dataset encompassing 9.56 million pairs
- evaluation benchmark consisting of 3,800 images.
[CVPR 2025] LLMDet: Learning Strong Open-Vocabulary Object Detectors under the Supervision of Large Language Models
https://github.com/iSEE-Laboratory/LLMDet
通过利用大语言模型同时生成图像级的详细描述和区域级的粗粒度定位短语,检测器能够从详细描述中获取更多信息和对图像更全面的理解,并构建出丰富的视觉-语言表示。
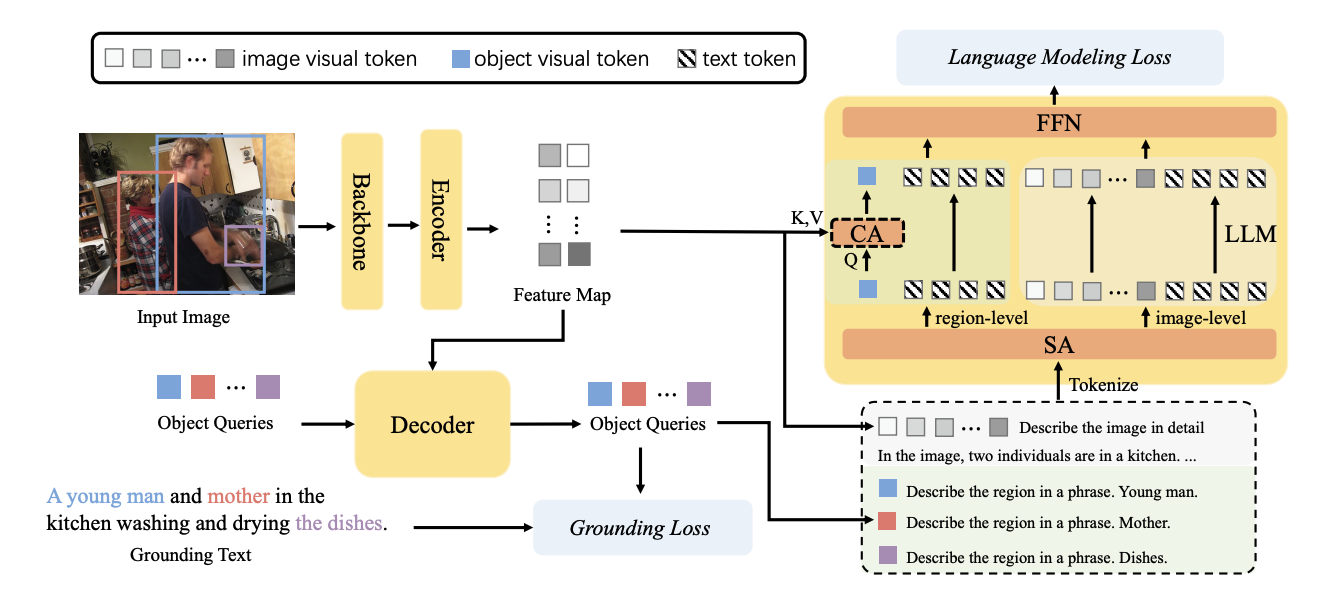
Feature Map输入到LLM中,训练LLM输出详细的image-level caption
object query输入到LLM,训练LLM输出与之对应的region-level caption
这样训练的Detector,可以有更丰富的语义信息,从而在open- vocabulary detection中有更好的结果
[CVPR 2025] ROD-MLLM: Towards More Reliable Object Detection in Multimodal Large Language Models
2025.8.24 代码未开源
- Motivation:现如今LLM,在面对referring以及grounding问题时,如果指代的目标没有出现在图片中,LLM并不会告知目标不存在,而是错误的给出不可信的目标框
但论文中的方法部分似乎并没有很详细的介绍其模型架构是如何思考相关指代语句是否存在于图片中,更多的是在训练数据集中引入了相关的训练数据
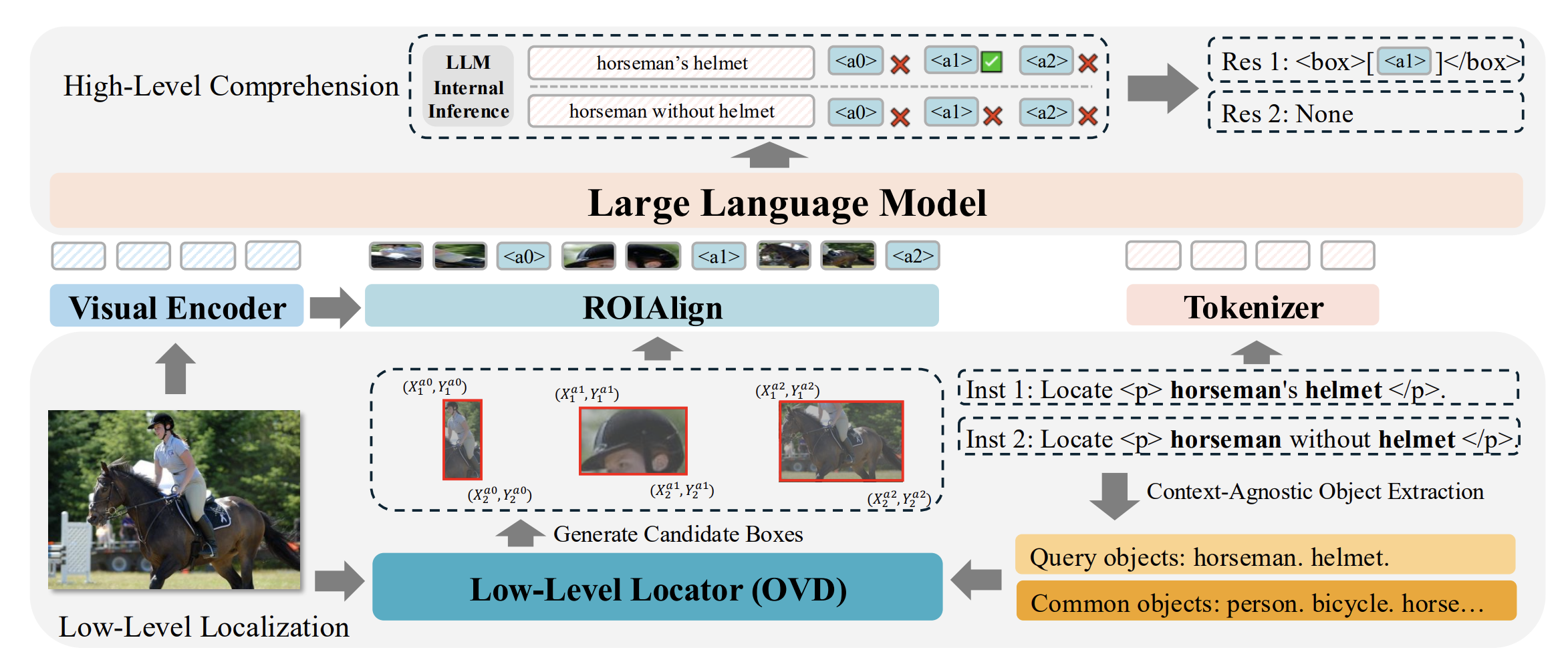
模型在输出框的时候并非输出坐标,而是利用Low-Level Locator预先对图片中的物体进行open vocabulary detection给出粗糙的框,然后在LLM输出这些框的标号,类似于ChetRex
- ROI Align
- 输入为图片坐标系下的box坐标
- 将图片坐标系转换为特征图坐标系
- 将特征图坐标下的box划分为8*8的网格
- 每一个网格采样,在特征图的feature下做双线性插值,得到region feature $\in \mathbb{R}^{8 \times 8 \times D}$
Visual Prompt
[NIPS 2023] Fine-Grained Visual Prompting
https://github.com/ylingfeng/FGVP
作者给出了不同于以往的coarse mask的处理方式,而是更细致的给出VLM需要关注的区域,从而提高任务的准确性

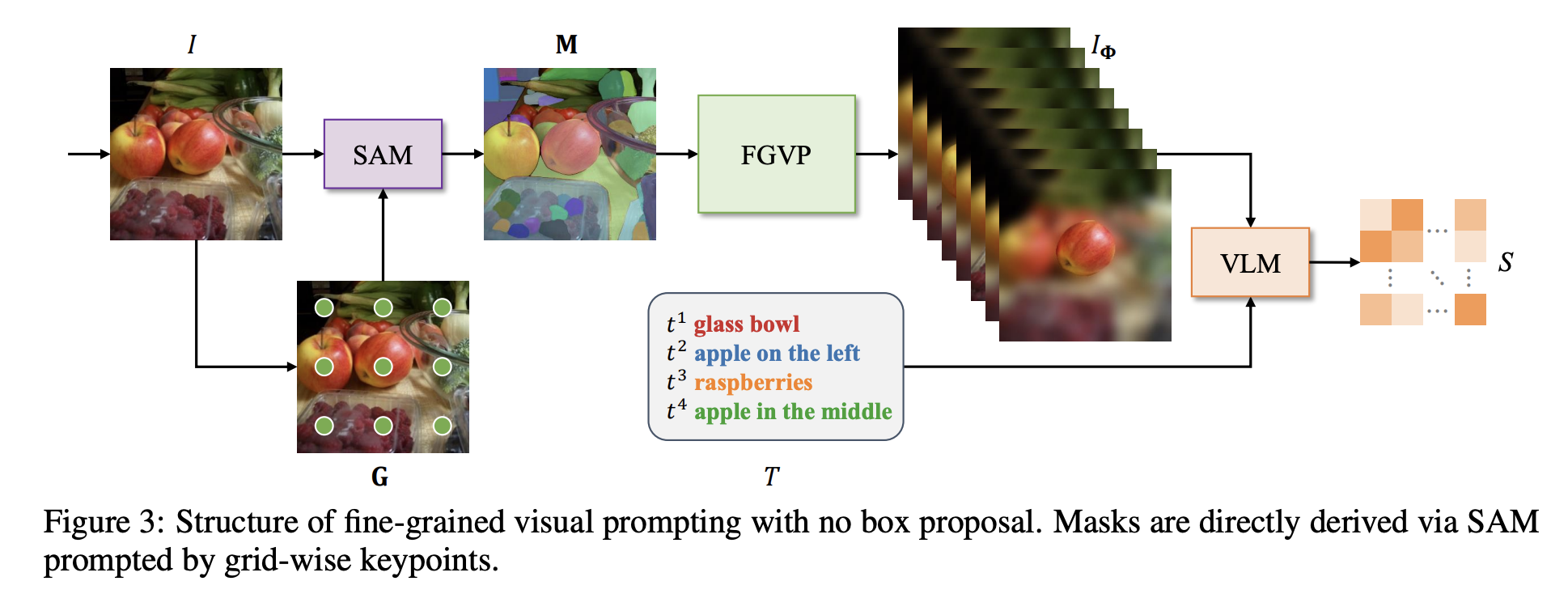
利用SAM可以给出更准确的semantic mask,再通过color,contour,grayscale,blur等后处理技术,得到下游任务需要的visual prompt
[ECCV 2024] GPT4RoI: Instruction Tuning Large Language Model on Region-of-Interest
https://github.com/jshilong/GPT4RoI
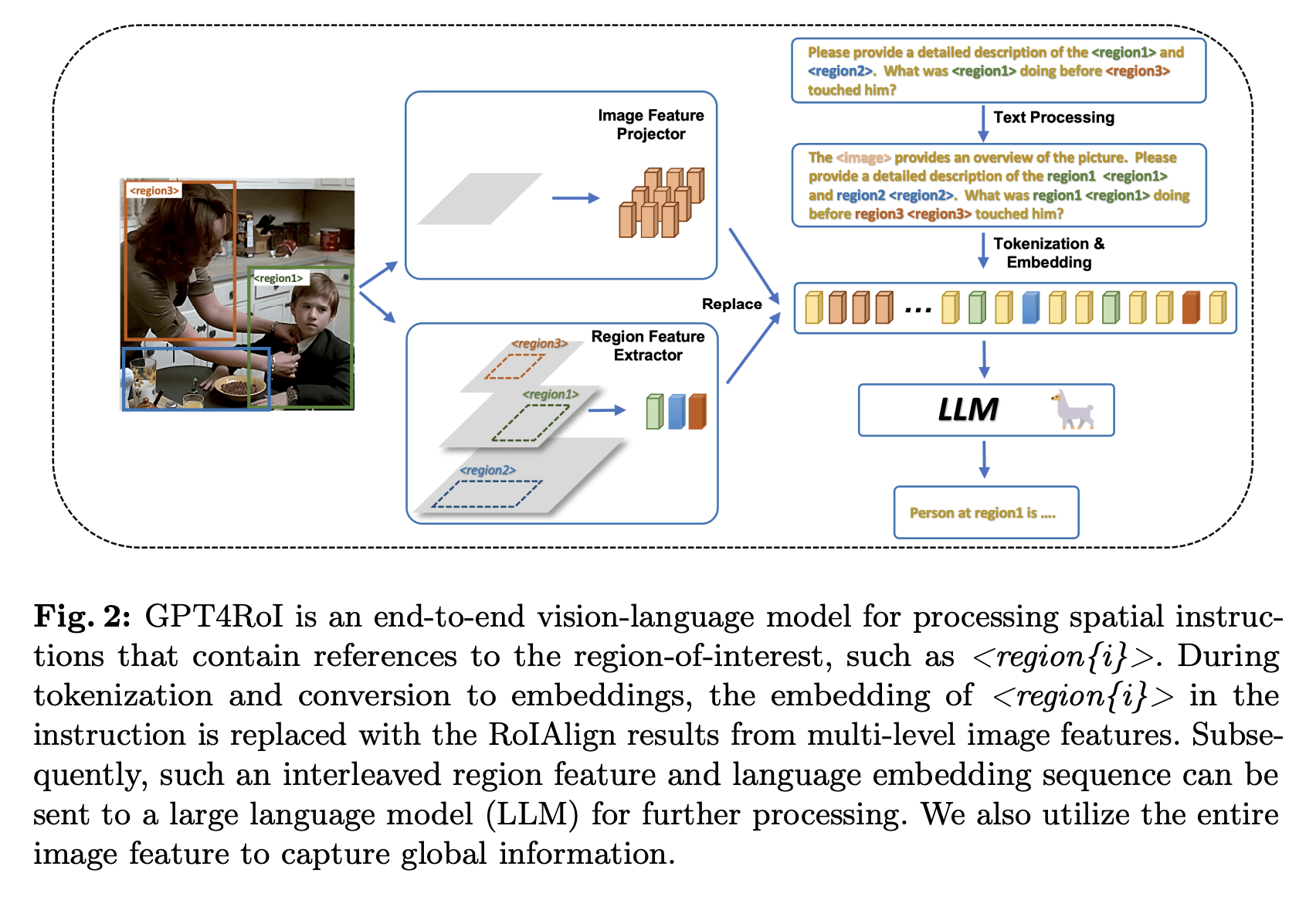
利用RoIAlign将RoI进行编码输入到LLM中,通过训练使得LLM可以理解Region,并对相关region-text pairs进行理解
- Training:
- pre-training:将region extractor对其到LLM,只训练region extractor参数
- End-to-end fine-tuning:MLM
[CVPR 2024] ViP-LLaVA: Making Large Multimodal Models Understand Arbitrary Visual Prompts
https://github.com/WisconsinAIVision/ViP-LLaVA
能够解码任意的视觉提示。这使得用户可以通过诸如“红色边框”或“箭头指示”等自然直观的方式来标记图像并与模型交互。
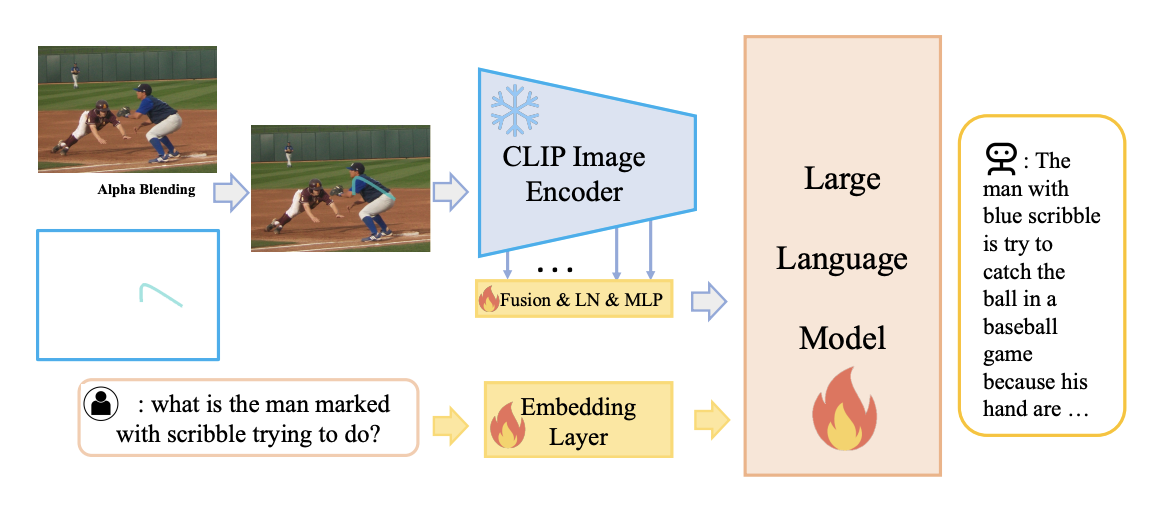
直接将visual prompt通过alpha blending融合进原始图片中,通过vision encoder输出img feature训练LLM。其中vision encoder输出的feature融合了CLIP多层次的输出,以求获得各种尺度下的图像细节。
自主构建了visual prompting的数据集,涵盖矩形、椭圆、点、三角形、掩码、掩码轮廓、箭头、涂鸦8种视觉提示
[CVPR 2024] Osprey: Pixel Understanding with Visual Instruction Tuning
https://github.com/CircleRadon/Osprey
先前工作均用coarse box作为visual prompt做region understanding,但这样粒度的提示还是太过粗糙,不能理解pixel-level的信息。Osprey模型可以理解pixel-level的semantic mask,进而引导LLM进行更细粒度的图片理解
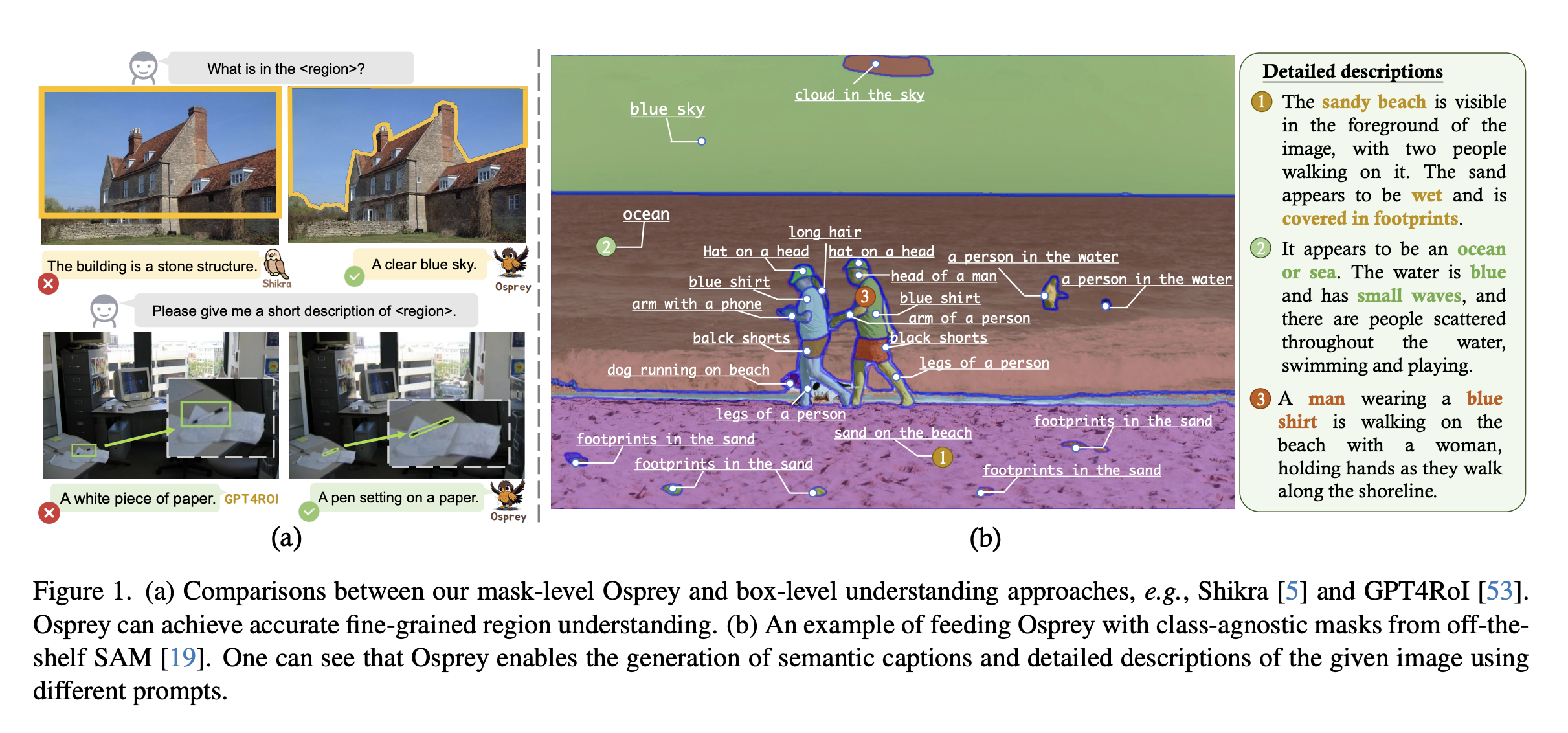
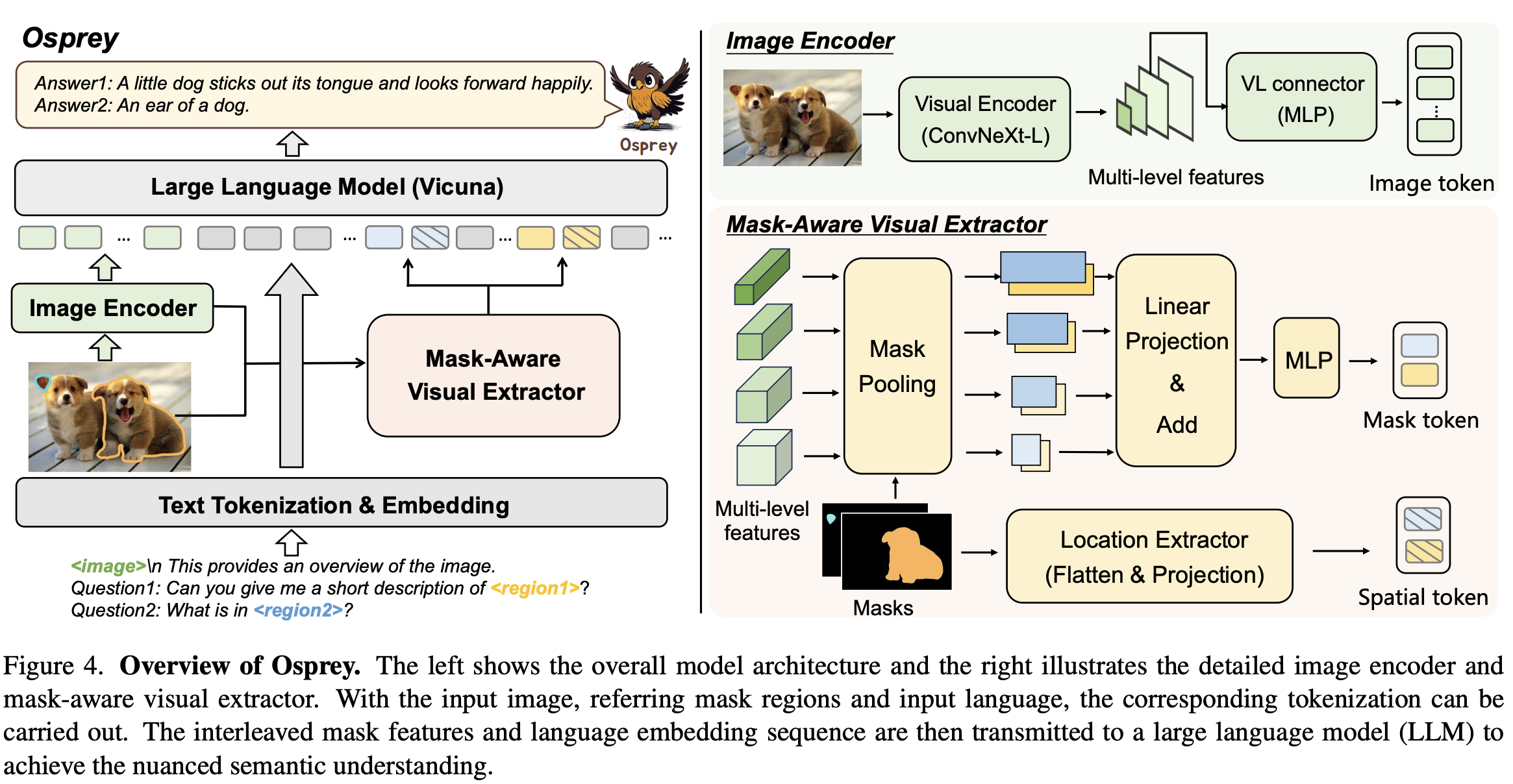
- 架构:
- Vision Encoder:CNN-based CLIP encoder,可以规避transformer因为高分辨率引入的计算负担
- Mask-Aware Visual Extractor:将CLIP中提取的多尺度特征,通过mask进行mask pooling
- spatial token:将mask调整为224*224,flatten之后project为spatial token
- 训练:
- Image-Text Alignment
- Mask-Text Alignment
- End-to-End Fine-tuning
[NIPS 2024] Visual CoT: Advancing Multi-Modal Language Models with a Comprehensive Dataset and Benchmark for Chain-of-Thought Reasoning
large-scale Visual CoT dataset:
https://github.com/deepcs233/Visual-CoT
[NIPS 2024] VisionLLM v2: A Generalist Multimodal Large Language Model for Hundeds of Vision-Language Tasks
https://github.com/OpenGVLab/VisionLLM
- Contribution:
- 大一统模型:除了传统的文字生成以外,现在做detection,segmentation,pose estimation,image generation,image editing等上百种下游任务
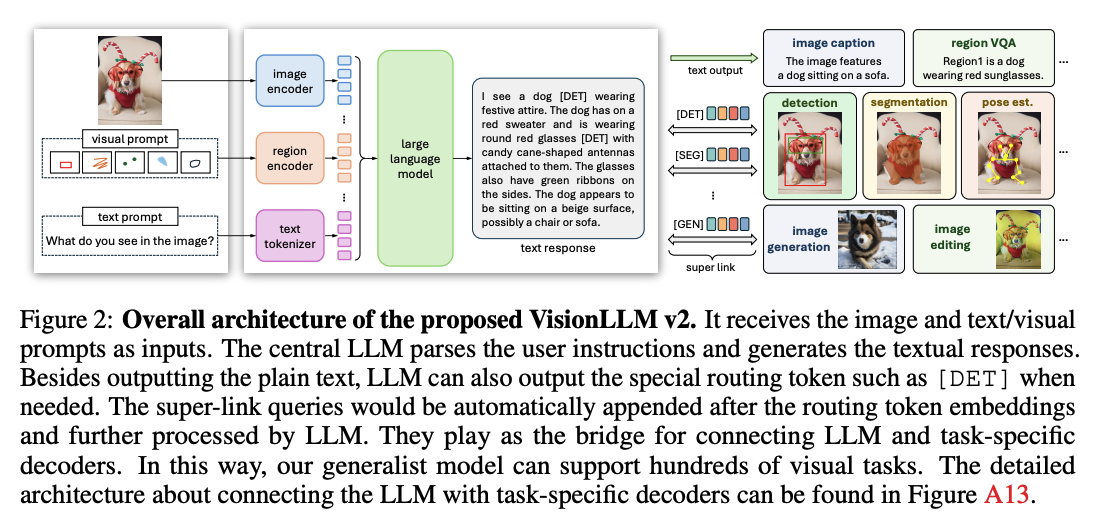
- Method:
- 想法相对简单,将所有需要用到的信息编码上token,通过让LLM输出特定的routing token([DET], [POSE], [SEG], [GEN], [EDIT]),将这些token在LLM输出层的feature接入下游任务的decoder,完成相应下游任务。
- routing token在输入层中有一系列可学习的token,在自回归训练中,如果输出层输出的是routing token,那么相应的可学习token则会被提取并输入到输入层中
- Training:
- LLaVa pre-training method:image,region,vision alignment and instruction tuning
- Multi-task joint training
- Decoder-only Fine-tuning
[25.02] Introducing Visual Perception Token into Multimodal Large Language Model
https://github.com/yu-rp/VisualPerceptionToken
- Motivation:MLLM无法自主的决定图片观察的侧重
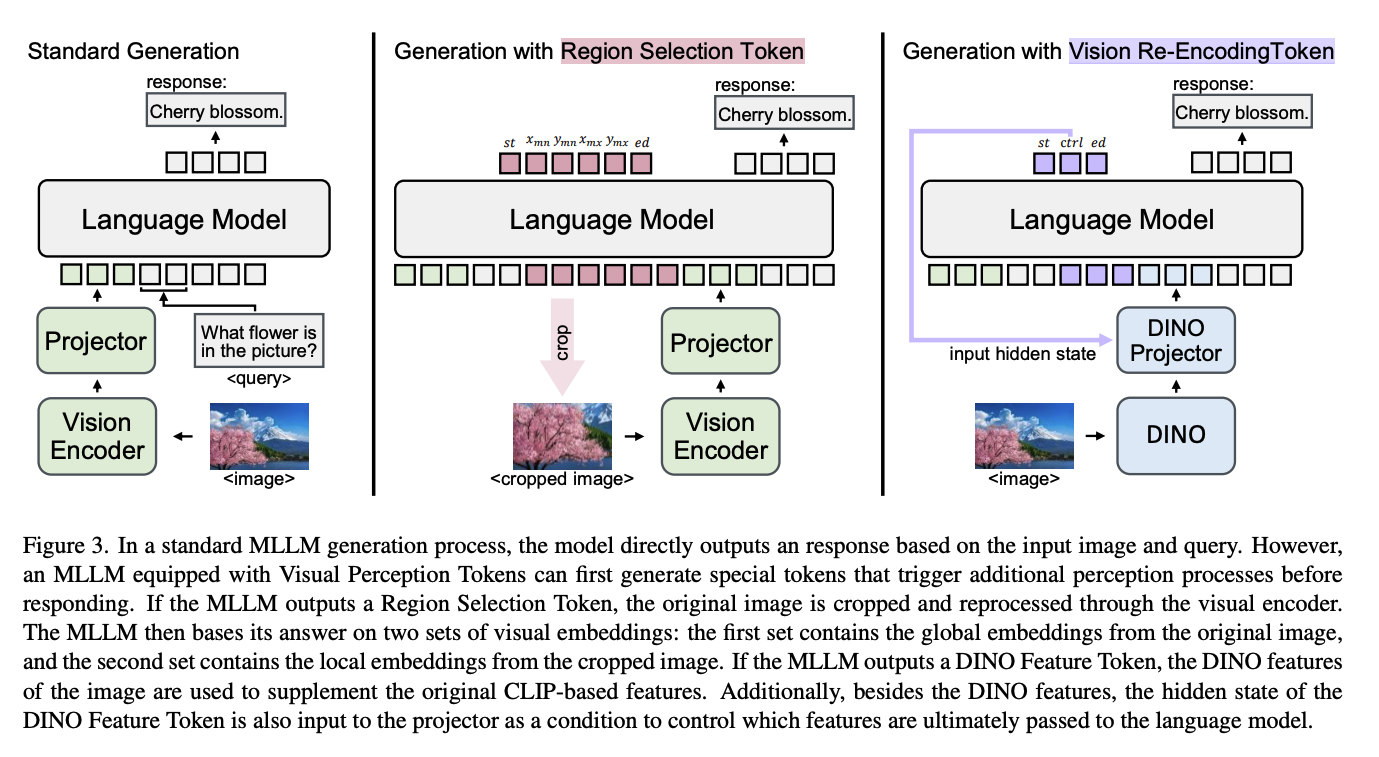
- Solution:提出两个额外的token:
- Region Selection Token:将图片进行裁剪之后append到输入层
- Vision Re-encoding Token:将图片用另外一个encoder进行处理
- 本质上为CoT
[25.02] Draw-and-Understand: Leveraging Visual Prompts to Enable MLLMs to Comprehend What You Want
主要贡献为数据集:a multi-domain dataset featuring 1.2 million image-visual prompttext triplets, including natural images, document images, scene text images, mobile/web
screenshots, and remote sensing images.
Draw-and-Understand: Leveraging Visual Prompts to Enable MLLMs to Comprehend What You Want
[25.03] ChatRex: Taming Multimodal LLM for Joint Perception and Understanding
https://github.com/IDEA-Research/ChatRex
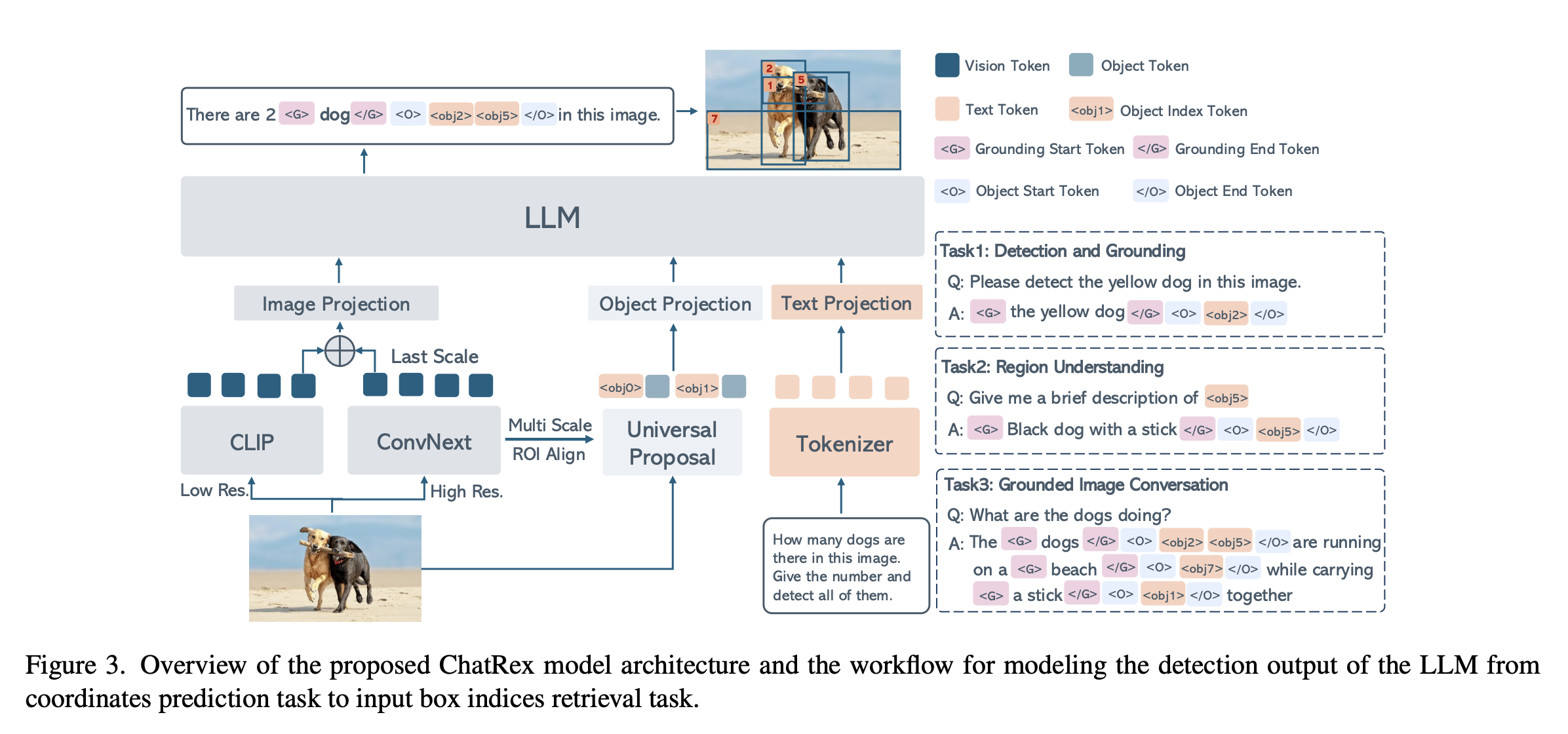
与其让LLM输出box的位置,不如提前训练一个object detector预先出框,再将框编码为object feature喂给LLM,让LLM依据图片以及文本信息,输出需要参考的object序号,这样可以直接通过序号查找到detector中已经检测到的对应object
[ICCV 2025] Referring to Any Person
https://github.com/IDEA-Research/RexSeek
通过文本引导,在图片中给出相对应的人物bounding box。整体框架构建于ChetRex
提供了一个基于人物box的数据集:HumanRef
Other
[CVPR 2025] Task Preference Optimization: Improving Multimodal Large Language Models with Vision Task Alignment
- Motivation:
- 现如今MLLM在fine-grained or precise understanding上表现不佳
- 需要将MLLM的回复Align with Human
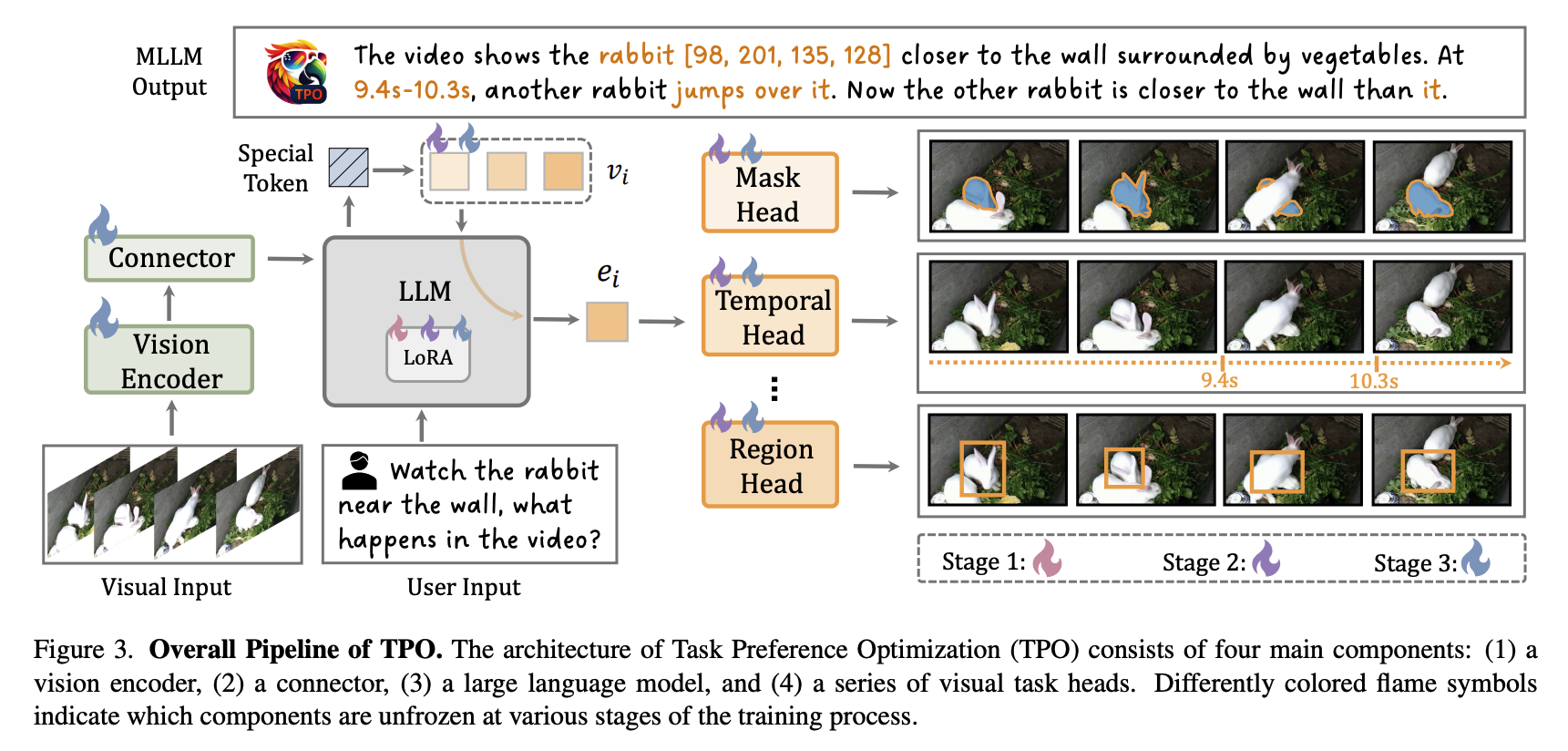
我目前为止没太看懂TPO是个什么玩意,暂且把它认为是“大力出奇迹”的方法。本质上我认为和“多阶段多任务联合微调”没有什么区别。但我不懂为什么加入了“玄乎其玄“的任务token $v_i$,以及任务头$H_i$。同时,我也不理解为什么这样的训练方法就可以使MLLM可以关注到fine-grained的信息,我更倾向于的原因是其在特殊任务上进行了特殊的训练,但这个偏工程做法,并不觉得是一个创新点。
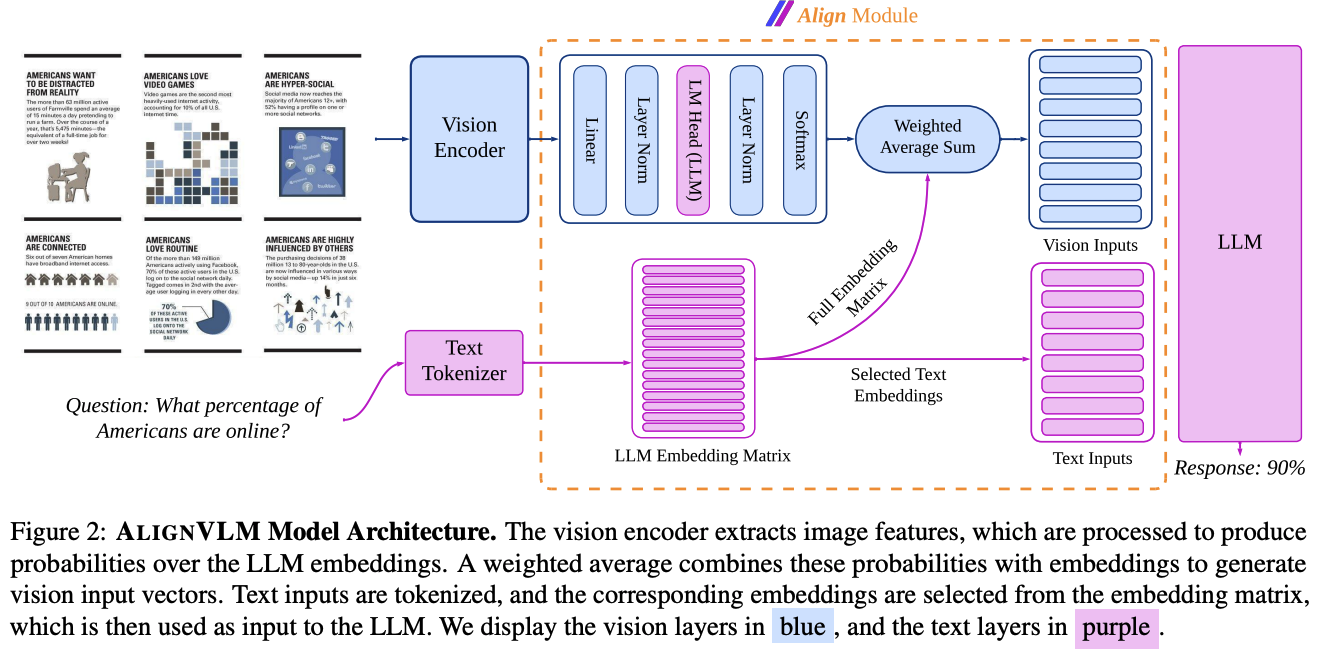
[25.02] ALIGNVLM: Bridging Vision and Language Latent Spaces for Multimodal Understanding
提出了一种新的多模态融合的方法
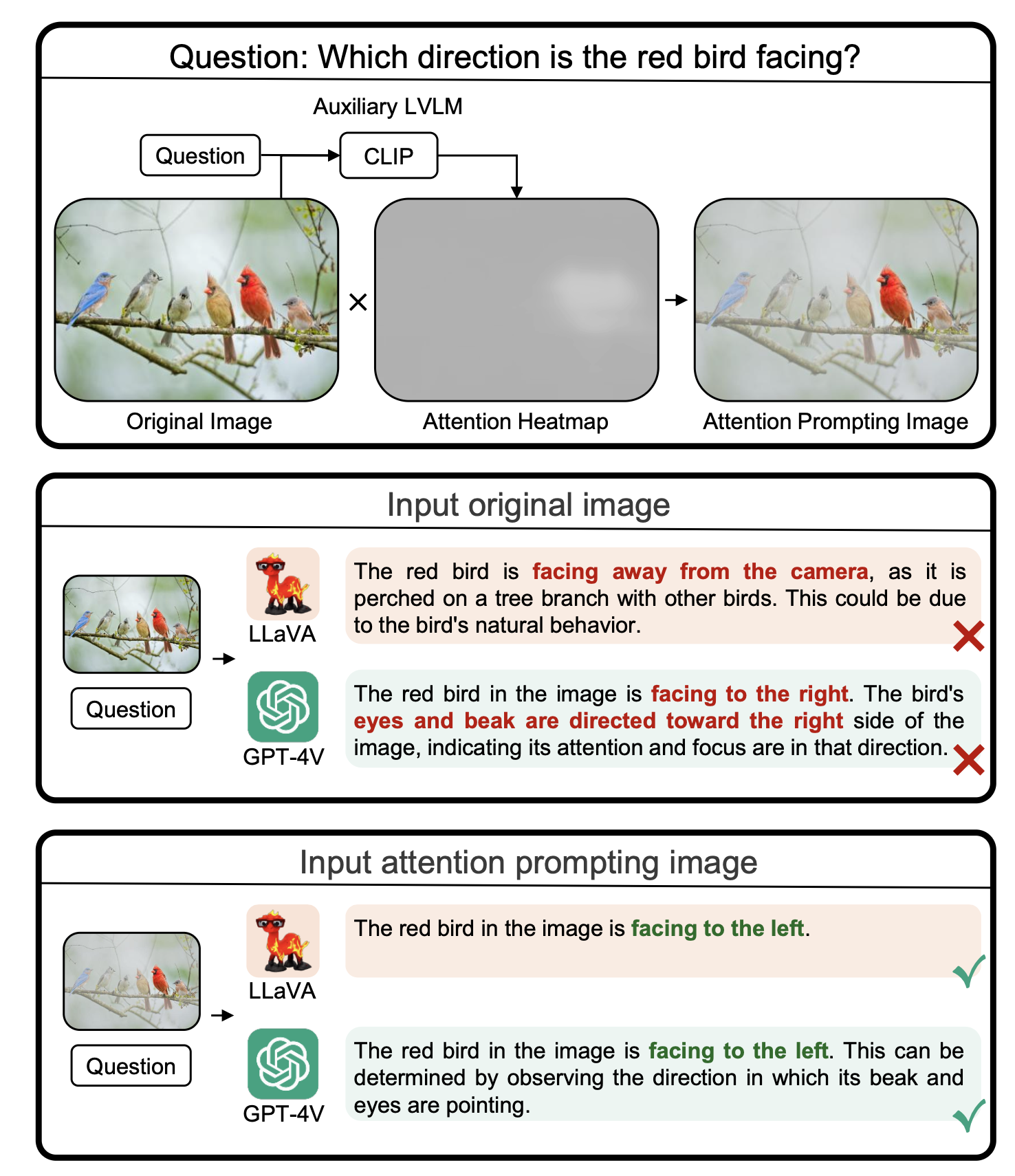
[ECCV 2024] Attention Prompting on Image for Large Vision-Language Models
https://github.com/yu-rp/apiprompting
本文通过对Visual Propmt叠加注意力图,可以有效改善LVLM在VQA中的表现。
[ECCV2024] FALIP: Visual Prompt as Foveal Attention Boosts CLIP Zero-Shot Performance
Motivation:
现有工作通常通过在图像上圈选或添加边界框等显式标注,引导 CLIP 聚焦于用户指定的区域。然而,这类方法不可避免地修改了原始图像,使输入到 CLIP 的内容不再完整。
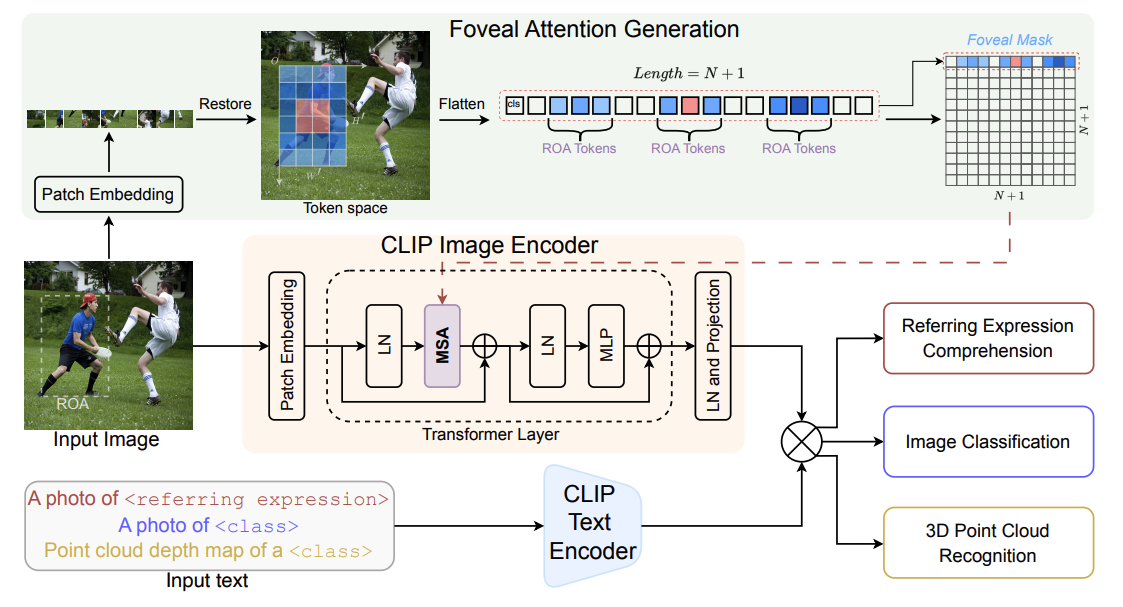
- Solution:通过预先标注边界框,并在 self-attention 中对对应的 patch 生成引导性掩码,从而在模型内部引导 CLIP 聚焦于标注区域。
[2025.06] Revisit What You See: Disclose Language Prior in Vision Tokens for Efficient Guided Decoding of LVLMs
https://github.com/bscho333/ReVisiT
Motivation: 在VQA以及image captioning任务中,LLM回复的text没有完全利用visual information → vision token在经过LLM之后会保存一定的语义信息
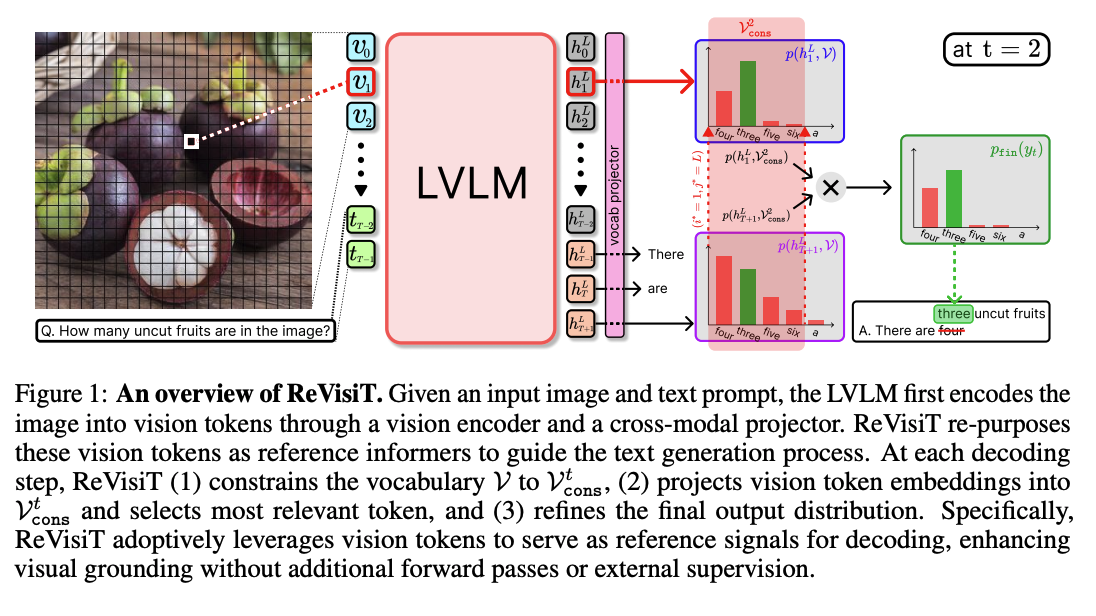
利用vision token在LLM output中的语义信息,与当前输出token的vocab分布进行重新分布,按照重新分布进行vocab输出
[CVPR 2025] LLaVA-ST: A Multimodal Large Language Model for Fine-Grained Spatial-Temporal Understanding
https://github.com/appletea233/LLaVA-ST
- Target:视频理解 → effectively handle both temporal and spatial localization
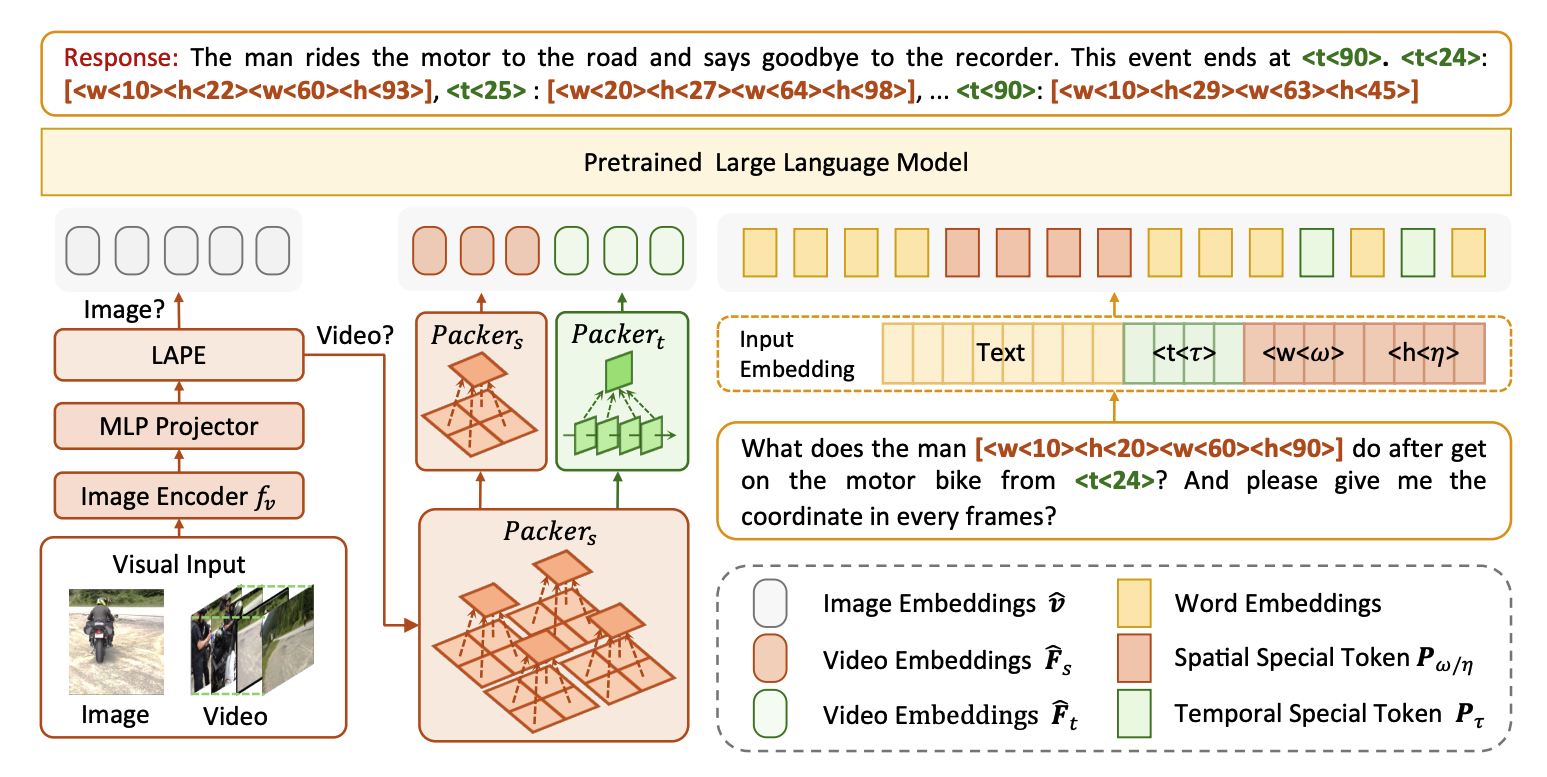
- Contribution:
- Language-Aligned Positional Embedding:将视频每一帧的每一个位置插入与其语义一致的embedding
- 选定$M_t$个关键帧,并将图片在长宽上进行$M_w, M_h$的均分,以获得在时空中的special token:$\langle t\langle \tau \rangle, \langle w\langle \omega \rangle, \langle h\langle \eta \rangle$
,其对应的input text embeddings为$p_\tau, p_\omega, p_\eta \in \mathbb{R}^D$ - 取pre-train LLM最后一层的矩阵 $W_o \in \mathbb{R}^{(V + M_w + M_h + M_t) \times D}$,设 $\hat{p_\tau}, \hat{p_\omega}, \hat{p_\eta} \in \mathbb{R}^D$ 为 $W_o$ 对应special token的行
- 则对应的position embeddings为 $\rho (\omega, \eta, \tau) = \frac{1}{2}(\hat{p_\tau}+ \hat{p_\omega}+ \hat{p_\eta} + p_\tau+ p_\omega+ p_\eta)$,则 $\rho \in \mathbb{R}^{M_w \times M_h \times M_t \times D}$
- 假设经过ViT的video feature大小为$N \times H_1 \times W_1 \times D$,则对$\rho$进行linear interpolation将其转换到image feature合适的大小
- 选定$M_t$个关键帧,并将图片在长宽上进行$M_w, M_h$的均分,以获得在时空中的special token:$\langle t\langle \tau \rangle, \langle w\langle \omega \rangle, \langle h\langle \eta \rangle$
- Spatial-Temporal Packer:获取视频的时空feature
- 经过embedding,feature $F$ 的大小为$N\times H_1 \times W_1 \times D$,将其reshape为$(k_1 \times k_1 \times N)\times (\frac{W_1}{k_1}\times \frac{H_1}{k_1}) \times D$,对每一个patch经过average pooling,得到$F^{‘} \in \mathbb{R}^{k_1 \times k_1 \times N \times 1 \times D}$。$F$与$F^{‘}$进行pixel-region attention得到$\hat{F} \in \mathbb{R}^{k_1 \times k_1 \times N \times D}$
- 用同样的方法对$\hat{F}$进行$k_2 \times k_2$下采样,得到$\hat{F_s} \in \mathbb{R}^{k_2 \times k_2 \times N \times D}$
- 将$\hat{F}$ reshape为$k_1 \times k_1 \times \sigma \times (\frac{N}{\sigma} \times D)$,做同样的操作得到$\hat{F_t} \in \mathbb{R}^{k_1 \times k_1 \times \sigma \times D}$
- Language-Aligned Positional Embedding:将视频每一帧的每一个位置插入与其语义一致的embedding
